Knowledge
Management Driven e-Learning System: Developing An Automatic Question Answering
System With Expert Locator
Ahmad Mukhlason, Ahmad Kamil
Mahmood, Noreen Izza Arshad, Universiti Teknologi PETRONAS ,
Malaysia
ABSTRACT:
e-Learning has shown an increase in the percentage of usage not only in the training and education organization, but also in other organization either profit or non-profit. However, the early promise of e-Learning has not been fully realized, the experience of e-Learning for many years has been no more than a handout published online. The emerging e-Learning requirements needs an e-Learning system which can solve user problem on demand. This paper presents the development of an automatic question answering system in knowledge management driven e-Learning system which can cope with user question expressed in Natural Language (English) by giving relevant answer taken from frequently asked questions (FAQs), related learning material, and recommended expert user. To improve the performance of the automatic question answering system we introduce an Ontology based expert locator framework in this paper. The experimental results showed that 85.07% of answers given by the system were satisfied.
Keywords: Automatic question & answering
system, e-Learning, Knowledge management, Ontology-driven expert locator
1. Introduction
Although E-learning has been implemented and become a trend in this knowledge age, the early promise of e-learning - that of empowerment - has not been fully realized. As stated by Steve O’Hear in Downes (2007), the experience of e-learning for many has been no more than a hand-out published online, coupled with a simple multiple-choice quiz - hardly inspiring, let alone empowering. Using new web services, e-learning has the potential to become far more personal, social and flexible.
An efficient e-Learning system should provide learners with learning environment that has high degree of freedom. In order to realize this, e-Learning systems must be equipped with functions such as letting learners themselves choose appropriate learning contents and means to understand correctly their level of progress and achievement for each learning contents (Downes, 2007). It should also be able to respond to the user problem at hand and allow user to access knowledge in a non-linear manner, allowing direct access to knowledge in whatever sequence makes sense for the situation at hand (Mukhlason, 2007).
Maurer and Sapper (2001) argued that e-learning has to be seen as a part of the general framework of knowledge management. These authors said that when documents are available to e.g. 100000 users, then after the first 1000 users have seen them and asked questions and the questions have been answered by experts, the other 99.000 users are very likely to ask similar question. The knowledge management (KM) system remembers all questions asked and their answers. When someone else types a question the system “only” has to decide whether a semantically equivalent question has been already asked before, and if so, the system can give the answer without expert consultation.
To cope with these problems the main contribution of this paper is to develop an automatic question answering system (AutoQAS) in e-learning system which is developed within a knowledge management system framework. In other word we implemented a knowledge management system to enhance the current state of e-learning system.
The AutoQAS receives user questions expressed in a Natural Language (English) not in keyword. Then AutoQAS can automatically answer the question by invoking knowledge base containing frequently asked questions (FAQs) and the corresponding character vector (CV). AutoQAS also suggests relevant learning material to user by invoking learning resource base and corresponding character vector (CV) which describe the content of learning material. If no feasible answer can be found or user I not satisfied with the answer given, AutoQAS forwards the question to the appropriate expert user using expert locator framework. Once the question is answered by the expert user, the FAQs database will be updated, such that the AutoQAS will be able to answer a similar question automatically. It means that the more system is used the more intelligent it becomes.
2. Relevant Work
Judy C.R. Tseng et al. developed an automatic customers service system (ACSS) on the internet, which can automatically handle customer requests sent via email, by analyzing the contents of the requests and finding the most feasible answer from the frequently asked question(FAQ) database as described in (Tseng & Hwang, 2007). The experimental result of ACSS showed that over 87.3% of users were satisfied with the replies given by the system.
Researchers have developed automatic question answering systems in e-learning system (Jemni & Ben, 2005; Hung et al, 2005; Wang et al, 2007) with different approaches. But none of them has implemented expert locator framework in invoking answer which will be given to user, although expert locator is very important aspect if we view e-learning as a knowledge management system.
Jemni & Ben (2005) developed an answering tool for e-learning environment called PERSO which answers user questions by invoking FAQs database; if the system does not find exactly the same question saved in the database, then it proceed to refinement (fuzzy treatment) of the collected questions by using the meta data of each question introduced by a tutor in FAQs database.
Hung et al (2005) applied word sense disambiguation algorithm to question answering system
for e-learning. Word sense disambiguation method is a hybrid approach
that combines a knowledge-rich source, wordnet (http://wordnet.princeton.edu)
with a knowledge-poor source, the Internet (World Wide Web) search. The words
in context are paired, and each word is disambiguated by searching the Internet
with queries formed using different senses of each of the two words. The senses
are then ranked according to the number of search hits. In this way all the
words are processed and senses are ranked.
Wang et al (2007) developed enhanced semantic question answering system for e-learning environment which answer user question by mapping semantic tree generated from the input sentence and relevance wordnet with data structure course ontology.
3. Framework Of AutoQAS
The framework of our AutoQAS is depicted in Figure 1. Roughly the AutoQAS framework can be explained as below:
1. User enter question expressed in natural language (English); this differs from traditional search engine which is keyword based. The AutoQAS can handle input in natural language (English). Accordingly, invoke the Question Identification Module. It extract the question entered by user into character vector (CV) describing the question by decomposing the question into several terms defined in keyword database.
2. Invoke the Best-Fit Answer Finding Module to select the best answer from knowledge base that consists of FAQs database and corresponding CV, and select the most relevant learning materials (LMs) from learning resource base that consists of LMs and corresponding CV, using similarity comparison algorithm.
3. Supply the answer and relevant learning material(s) to the user.
4. User gives feedback whether (s)he is satisfied or unsatisfied.
5. If the user is not satisfied with the answer, the AutoQAS invoke the Expert locator Module. This module find user (tutor,lecturer) who is the expert in user question area and send the question to the user expert.
6. Once the question is answered by the expert user, the FAQs database will be updated such that the AutoQAS will be able to answer the similar question automatically.
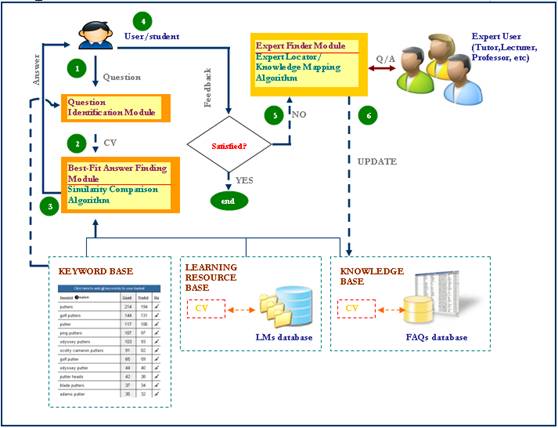
Figure 1: AutoQAS Framework
4. Information Retrieval
Algorithm Of AutoQAS
The idea of automatic question answering system is same for information retrieval which has become a well known research area in computer and information sciences. (Grossman et al, 2006). Classified retrieval strategy in information retrieval divides into three types:
1. Manual system consist of Boolean, fuzzy set, and inference network technique
2. Automatic system, consist of vector space model and latent semantic indexing technique
3. Adaptive system, consists of probabilistic, genetic algorithm, and neural network technique
In this section we shall present the information retrieval of AutoQAS based on the notations from the result of previous investigation namely vector space model processing and frequency of the occurrence of query terms as presented in Tseng & Hwang (2007). While the Boolean model has the disadvantage that it uses only binary comparison between terms in the query and the documents, the vector space model recognizes that it is not sufficient and uses non-binary weighting of index terms. The weighting of index terms is made possible by the Term Frequency (TF)-Inverse Document Frequency (IDF) algorithm. Then the degree of similarity between the query and the document can be calculated as cosine value on the angle between the query vector and document vector.
The advantages of using vector retrieval model is first and foremost that by using a non-binary weighting scheme on the index term one gets a good retrieval performance. And by using the cosine ranking the user issuing the query gets presented with relatively similar documents because of the partial match strategy and results ranked by relevance (Richardo & Berthier, 1999).
4.1. Question
Analysis Algorithm
The question entered by the user needs to be extracted into
characteristic vector (CV) which describe the question. Accordingly the CV is
analyzed using TFxIDF technique. The Term Frequency (TF) measures how well an
index term describes the document content by assigning height weight to a term
that frequently occurs in a document. The inverse document frequency (IDF) on
the other hand measures how well the index term discriminates between relevant
and non-relevant documents in the collection by giving high weights to rare
terms. The original TFxIDF Formulas is given as follows (Christoper et al,
2008):
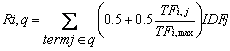 (1)
(1) (2)
(2)
Where Di is i-th document for 1<i<N, Qj is j-th query term in q for 1<j<M, TFi,j is number of occurance for Qj in Di, TFi,max is maximum number of occurances for the key term in Di and Ci,j=1 if Di Contains Qj, and Cij=0 otherwise.
As TFxIDF aims at taking both the term (keyword) frequency in a specified
document and its frequency in the entire documents into consideration, for a
set of questions Q=
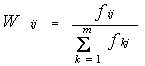 (3)
(3)
CV(Qi)
=
where Kj represents jth keyword
and fij is the number of occurances
of Kj in Question Qi, ![]() is the total number of occurrences of Kj in the FAQ database.
is the total number of occurrences of Kj in the FAQ database.
Assume that there are five FAQ’s in the FAQ database. The question part
of FAQ database is showed in Table 1
and the answer part is showed in Table
2. Then the keyword set and the number of occurrences of each keyword
from the keyword database is depicted in Table 3. The keyword, number of occurrences, and the weight of each
question in Table 1 are depicted
in Table 4.
Table 1: Question Part of FAQs Database
|
QuestionID |
Question |
|
Q1 |
How should I decide which integer data type to use in declaration of a variable? |
|
Q2 |
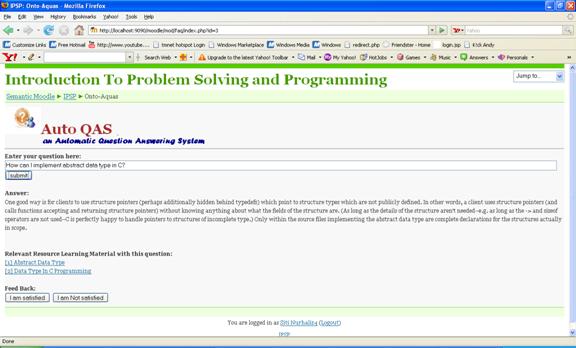
How can I implement abstract data type in C? |
|
Q3 |
How can I ensure that integer arithmetic doesn't overflow? |
|
Q4 |
What's the difference between the unsigned preserving and value preserving rule? |
|
Q5 |
What am I allowed to assume
about the initial value of variable and array
which are not explicitly initialized?
|
Table 2: Answer Part of FAQs Database
|
QuestionID |
Answer |
|
Q1 |
If you might need large values (above 32,767 or below -32,767), use long. Otherwise, if space is very important (i.e. if there are large arrays or many structures), use short. Otherwise, use int. If well-defined overflow characteristics are important and negative values are not, or if you want to steer clear of sign-extension problems when manipulating bits or bytes, use one of the corresponding unsigned types. |
|
Q2 |
One good way is for clients to use structure pointers (perhaps additionally hidden behind typedefs) which point to structure types which are not publicly defined. In other words, a client uses structure pointers (and calls functions accepting and returning structure pointers) without knowing anything about what the fields of the structure are. (As long as the details of the structure aren't needed--e.g. as long as the -> and sizeof operators are not used--C is perfectly happy to handle pointers to structures of incomplete type.) Only within the source files implementing the abstract data type are complete declarations for the structures actually in scope. |
|
Q3 |
The usual approach is to test the operands against the limits in the header file <limits.h> before doing the operation. For example, here is a ``careful'' addition function: intchkadd(int a, int b){ if(INT_MAX - b < a) {fputs("int overflow\n", stderr); return INT_MAX; } return a + b;}
|
|
Q4 |
These rules concern the behavior when an unsigned type must be promoted to a larger type. Should it be promoted to a larger signed or unsigned type? (To foreshadow the answer, it may depend on whether the larger type is truly larger).Under the unsigned preserving (also called sign preserving') rules, the promoted type is always unsigned. This rule has the virtue of simplicity, but it can lead to surprises (see the first example below). Under the value preserving rules, the conversion depends on the actual sizes of the original and promoted types. If the promoted type is truly larger--which means that it can represent all the values of the original, unsigned type as signed values--then the promoted type is signed. If the two types are actually the same size, then the promoted type is unsigned (as for the unsigned preserving rules). Since the actual sizes of the types are used in making the determination, the results will vary from machine to machine. On some machines, short int is smaller than int, but on some machines, they're the same size. On some machines, int is smaller than long int, but on some machines, they're the same size. |
|
Q5 |
Uninitialized variables with static duration (that is, those declared outside of functions, and those declared with the storage class static), are guaranteed to start out as zero, just as if the programmer had typed ``= 0'' or ``= {0}''. Therefore, such variables are implicitly initialized to the null pointer, if they are pointers, and to 0.0 if they are floating-point. Variables with automatic duration (i.e. local variables without the static storage class) start out containing garbage, unless they are explicitly initialized. (Nothing useful can be predicted about the garbage.) If they do have initializers, they are initialized each time the function is called. These rules do apply to arrays and structures arrays and structures are considered ``variables'' as far as initialization is concerned. When an automatic array or structure has a partial initializer, the remainder is initialized to 0, just as for statics. Finally, dynamically-allocated memory obtained with malloc and realloc is likely to contain garbage, and must be initialized by the calling program, as appropriate. Memory obtained with calloc is all-bits-0, but this is not necessarily useful for pointer or floating-point values. |
Table 3: Number of Occurrence for Each
Keyword
|
ID |
Keyword |
Occurrence |
|
K1 |
Decide |
1 |
|
|
Integer |
2 |
|
K3 |
Data type |
2 |
|
K4 |
Implement |
1 |
|
K5 |
Abstract |
1 |
|
K6 |
C |
1 |
|
K7 |
Ensure |
1 |
|
K8 |
Arithmetic |
1 |
|
K9 |
Overflow |
1 |
|
K10 |
Difference |
1 |
|
K11 |
Unsigned |
1 |
|
K12 |
Preserving |
2 |
|
K13 |
Value |
1 |
|
K14 |
Rule |
1 |
|
K15 |
Initial Value |
1 |
|
K16 |
Variable |
3 |
|
K17 |
Array |
1 |
|
K18 |
Initialized |
1 |
|
K19 |
Global |
1 |
|
K20 |
Null |
1 |
|
K21 |
Pointer |
1 |
|
K22 |
Floating-point |
1 |
|
K23 |
Declaration |
1 |
Table 4: Keyword, Number of Occurrence,
and Weight for Each uestion in FAQ Database
|
Keyword |
Occurrence |
Wj |
|
|
||
|
Question 1 (Q1) : |
||
|
Decide(K1) |
1 |
1/1 |
|
Integer( |
1 |
1/1 |
|
Data type(K3) |
1 |
1/2 |
|
Declaration(K23) |
1 |
1/1 |
|
Variable(K16) |
1 |
1/3 |
|
|
||
|
Question 2 (Q2) : |
||
|
Implement(K4) |
1 |
1/1 |
|
Abstract(K5) |
1 |
1/1 |
|
Data type(K3) |
1 |
1/2 |
|
C(K6) |
1 |
1/1 |
|
|
|
|
|
Question 3 (Q3) : |
||
|
Ensure(K7) |
1 |
1/1 |
|
Integer( |
1 |
1/2 |
|
Arithmetic(K8) |
1 |
1/1 |
|
Overflow(K9) |
1 |
1/1 |
|
|
|
|
|
Question 4 (Q4) : |
||
|
Difference(K10) |
1 |
1/1 |
|
Unsigned(K11) |
1 |
1/1 |
|
Preserving(K12) |
2 |
2/2 |
|
Value(K13) |
1 |
1/1 |
|
Rule(K14) |
1 |
1/1 |
|
|
|
|
|
Question 5 (Q5) : |
||
|
Initial Value(K15) |
1 |
1/1 |
|
Variable(K16) |
2 |
2/3 |
|
Array(K17) |
1 |
1/1 |
|
Initialized(K18) |
1 |
1/1 |
|
Global(K19) |
1 |
1/1 |
|
Null(K20) |
1 |
1/1 |
|
Pointer(K21) |
1 |
1/1 |
|
Floating-point(K22) |
1 |
1/1 |
According to Table 4, each question in in FAQs database as depicted in Table 1 can be represented as the following concept vectors:
CV(Q1)= CV(Q2)= {(K3,1/2), (K4,1/1), (K5,1/1), (K6,1/1)} CV(Q3)= {( CV(Q4)= CV(Q5)=
Similarly, the CV of student question Q can be expressed as follows:
CV(Q)=
 (6)
(6)
For instance, the student question is demonstrated by Table 5, then the keywords and corresponding weights of the request are depicted in Table 6.
Table 5: Illustrative Example of
Student Question
|
Question |
|
How can I implement abstract data type in C Programming? |
Table 6: Keyword and the Corresponding
Weights of the Ilustrative Example
|
Keyword |
Occurrence |
Wj |
|
Implement(K4) |
1 |
1/1 |
|
Abstract(K5) |
1 |
1/1 |
|
Data type(K3) |
1 |
1/2 |
|
C(K6) |
1 |
1/1 |
4.2. Similarity Comparison
Algorithm
The next step need to do is calculate the similarity between the character vector (CV) of student question and the character vector (CV) of each question in FAQ database. In our approach, we employed inner product and Euclidian distance method to compute the degree of the similarity.
Inner Product Method is a matrix multiplication
method. The similarity between student question Q and FAQ i is given as
![]() (7)
(7)
For the example given above, we have the following similarity values by employing the inner product method:
Equation (8)
|
D1= |
(0 * 1/1) + (0 * 1/1) + (1/2 * 1/2) + (1/1 * 0) + (1/1 * 0) + (1/1 * 0) + (0 * 1/3) + (0 * 1/1) = 0.25 |
|
D2= |
(1/2 * 1/2) + (1/1 * 1/1) + (1/1 * 1/1) + (1/1 * 1/1) = 3.25 |
|
D3= |
(0 * 1/2) + (1/2 * 0) + (1/1 * 0) + (1/1 * 0) + (1/1 * 0) + (0 * 1/1) + (0 * 1/1) + (0*1/1) = 0.00 |
|
D4= |
(1/2 * 0) + (1/1 * 0) + (1/1 * 0) + (1/1 * 0) + (0 * 1/1) + (0 * 1/1) + (0 * 2/2) + (0 * 1/1) + (0 * 1/1) = 0.00 |
|
D5= |
(1/2 * 0) + (1/1 * 0) + (1/1 * 0) + (1/1 * 0) + (0 * 1/1) + (0 * 2/3) + (0 * 1/1) + (0 * 1/1) + (0 * 1/1) + (0 * 1/1) + (0 * 1/1) + (0 * 1/1) = 0.00 |
In Equation 8 we can see that, D2 is the maximum value, and hence the answer part of Q4 will be reply to student.
Euclidian Distance Method: By applying Euclidian distance method, the similarity between student’s question Q and FAQ i is given as
![]() ² (9)
² (9)
For the example given above, the Euclidian distance values of the student’s question and the question part of the FAQ’s in FAQ database are given as follows:
Equation (10)
|
D1= |
X=(0
- 1/1)2 + (0 - 1/1)2
+ (1/2 - 1/2)2 + (1/1 - 0)2
+ (1/1 - 0)2 + (1/1 - 0)2 + (0 - 1/3)2 + (0
- 1/1)2 =6.11.
|
|
D2= |
X=(1/2 - 1/2) + (1/1 - 1/1)2 + (1/1 - 1/1)2 + (1/1 - 1/1)2 = 0.00
|
|
D3= |
X=(0 - 1/2)2 + (1/2 - 0)2 + (1/1 - 0)2 + (1/1 - 0)2 + (1/1 - 0)2 + (0 - 1/1)2 + (0 - 1/1)2 + (0-1/1)2 = 6.50
|
|
D4= |
(1/2 - 0)2 + (1/1 - 0)2 + (1/1 - 0)2 + (1/1 - 0)2 + (0 - 1/1)2 + (0 - 1/1)2 + (0 - 2/2)2 + (0 - 1/1)2 + (0 - 1/1)2 = 8.25
|
|
D5= |
(1/2 - 0)2 + (1/1 - 0)2 + (1/1 - 0)2 + (1/1 - 0)2 + (0 - 1/1)2 + (0 - 2/3)2 + (0 - 1/1)2 + (0 - 1/1)2 + (0 - 1/1)2 + (0 - 1/1)2 + (0 - 1/1)2 + (0 - 1/1)2 = 10.69
|
In Equation 9, we can see that D2 is the minimum value, which implies that the student’s question Q is the most similar to the question Q2. This result is the same as that of the inner product method.
5. Document Retrieval
Algorithm Of AutoQAS
Principally, the algorithm for document retrieval from learning resource base is the same as information retrieval from FAQ’s database. The only thing to do is create character vector (CV) for each learning material (LM) in learning resource base and corresponding keyword describing the learning material. Then, the similarity measurement between student question’s CV and learning material’s CV is calculated as the same thing in information retrieval algorithm.
6. Expert Locator Module Of
AutoQAS
Vennesland and Audun in Vennesland (2007) proposed a model for finding and mapping expert automatically in corporate data which find expert by exploring employee record database and document, but in implementation this model has limitation i.e. low recall and low precision. In this paper we propose an ontology approach for finding expert in e-learning environment.
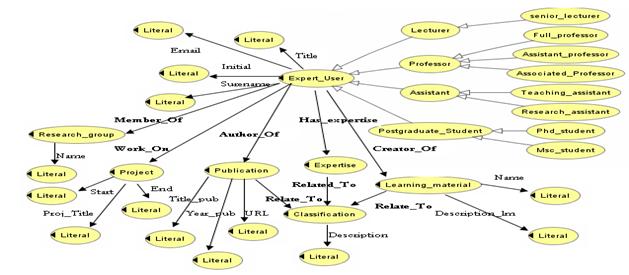
Previous investigation in expertise finding using ontology approach has been conducted in (Liu et al, 2002) by exploring RDF(Resource Description Framework) within organizational memory. But, as OWL(Web Ontology Language) than RDF is more powerful we reconstruct what has been proposed by Ping Liu et. al. as depicted in Figure 2.
|
|
|
Figure 2 Expert locator Module Architecture |
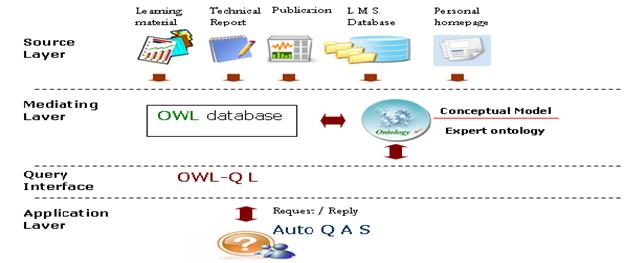
The architecture of expert locator module in Figure 2 can be explained as follows:
¨ Source layer: this layer contains data sources that are relevant to identifying the expertise of expert user (professor, lecturer, assistant/tutor) such as learning materials (LMs), technical report, and publications authored by expert user; e-learning management system (LMS) database which store information about courses tough by expert user; and personal homepage which includes personal contact information, research interest, associated research group(s), and recent publication
¨
Mediating layer: this layer maintains the conceptual model i.e.
expert ontology, and identifies which data sources are relevant to the query.
The ontology is depicted in Figure 3
¨ Query interface: this layer translated query from Auto QAS into ontology query language i.e. OWL-QL (Web Ontology Language-Query Language) and return the result to Auto QAS
¨ Application layer: this layer is AutoQAS (automatic question answering system)
![Text Box: Assume: t.idf gives the idf of any term t
q.tf gives the tf of any query term
Begin
Score[] ç0
For each term t in Query Q
Obtain posting list l
For each entry p in l
Score[p.docid] = Score[p.docid] + (p.tf * t.idf)(q.tf * t.idf)](articl164_files/image022.gif)