Using
A Taxonomy For Knowledge Audits: Some Field Experiences
Ravi S. Sharma, Melvyn Chia, Vironica Choo, Eyosore Samuel, Nanyang Technological University, Singapore
ABSTRACT:
The organisation of knowledge for exploitation and re-use in the modern enterprise is often a most perplexing challenge. The entire knowledge management life-cycle (for example – create, capture, organize, store, search, and transfer) is impacted by the organisation of intellectual capital into a corporate taxonomy or knowledge map (often used interchangeably). Determining the extent to which such an objective is achieved is part of the focus of what is known as a knowledge audit. In this practice-oriented article, the authors review the fundamentals of creating a taxonomy, the use of meta-data in a necessary process known as classification and the role of expertise locators where the knowledge is not explicit but resides within experts (ie. tacit knowledge). The authors conclude with a framework for conducting a knowledge audit based on the conceptual underpinnings of the corporate taxonomy. This framework is field tested in five distinct organizations for its practicability and effectiveness. It is hence the intent of the paper to provide such a useable framework for knowledge audits.
Keywords: Knowledge ontologies, Taxonomy tools, Taxonomy methods, Knowledge mobilization
1. Organising Corporate
Knowledge.
The organisation of knowledge resources is hardly a novel undertaking. The ancient libraries of
The collective knowledge of an organization is diffused
through several processes of
knowledge acquisition, sharing of acquired knowledge, and action initiated as a
consequence of new knowledge being created. This flow is illustrated in Figure
1. Nonaka and Takeuchi (1995) concluded
that “The Knowledge Creating Company” cannot create knowledge on
its own without the initiative of the individual and the interactions that take
place between individuals and groups.
The effective design of the organization makes it possible for the
knowledge content of many of these interactions to be captured.
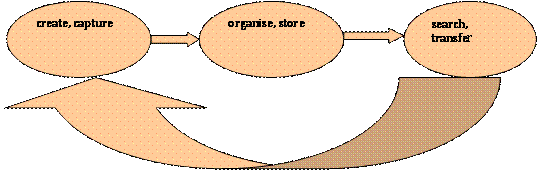
Figure 1: Knowledge Processes In Organisations.
Figure 1 also shows some of these fundamental knowledge processes within an organization. While there are several models for knowledge cycles (cf. Birkinshaw and Sheehan, 2002 – capture, store, transfer; Feldman and Sherman, 2001 – create, distribute, manage, retrieve, apply; Mohanty and Chand, 2005 – create, capture, organise, store, use;), the figure above is nevertheless a reasonable synthesis described in Foo et al. (2007). Knowledge workers create intellectual capital in the course of their work (or more precisely, as a result of their work) and the extent to which this may be captured is a measure of the organisation’s standard procedures or structural capital. The knowledge infrastructure within the organisation also drives how value (in the form of re-exploitable knowledge) is organised and stored. The competitive advantage of the organisation lies in the speed and precision with which its knowledge assets are searched and transferred as and when opportunities arise.
Hence the fundamental motivation for building a corporate taxonomy or knowledge map is the realization that knowledge is of little value unless it can be shared and re-used (as opposed to re-discovered) when opportunities for exploitation arise. There is considerable agreement that such a taxonomy is the basis for interactions and organizational learning (Cheung et al., 2005; Davenport and Prusak, 1998; Gilchrist and Kibby, 2000; Gilchrist 2001; Nonaka and Takeuchi, 1995; Potter 2001). The remainder of this article describes the building blocks of a corporate taxonomy and presents a framework for conducting what is known as a knowledge audit - an integral aspect of remaining competitive in the face of the continual deluge of (particularly, digital) knowledge. The framework is deployed in the field in order to test its practicability and effectiveness. Finally, the article concludes with some thoughts on developing taxonomies for knowledge auditability.
2. Building Blocks Of
Corporate Taxonomies.
The word taxonomy is derived from Greek words (tassein + nomos), which translates into the science of classification. The Swedish scientist Carl Linnaeus (1707 – 1778) was perhaps the first to use the idea of a taxonomy to classify the natural world. From its origins in the classification of living things, the idea of a taxonomy now has universal applications in grouping knowledge so that it can be systematically developed and re-used. In the information sciences, the study of corporate taxonomies has been a subject of considerable and longstanding interest among both researchers (cf. Cheung et al. 2005; Geisler 2006; Gruber 1993; Noy and McGuinness, 2001; Saeeh and Chaudhry, 2002; Vellucci 1997) as well as practitioners (cf. Conway and Sligar, 2002; Delphi 2002; Ernst & Young; Gilchrist and Kibby, 2000; Gilchrist 2001; Greif 2001; Lehman 2003; Pepper 2000; Potter 2001; Woods 2004).
To begin at the beginning, a modernist definition found in Lehman (2003): A taxonomy is a subject map to an organization’s content. [It] reflects the organization’s purpose or industry, the functions and responsibilities of the persons or groups who need to access the content, and the purposes / reasons for accessing the content.
Hence a corporate taxonomy may be viewed as a conceptual map, an information access tool, and a communications and training device at the same time, providing history, expertise and inside information that can assist every business activity. Naturally, as with any other information access tool, a taxonomy needs requirements and purposes before it is developed and exploited.
What then makes a corporate taxonomy effective, extendable and practical? The table below – a compilation from Gilchrist (2001), Graef (2001), Lehman (2003) and Woods (2004) – offers eight perspectives or families of taxonomic elements, which apply to an organization, although more perspectives do not necessarily translate to greater business effectiveness.
Table 1: Perspectives of Taxonomic Elements.
Industry Segments - Marketing / Positioning /
Competitive Intelligence Perspective; Industry Segments may overlap with
Products and Services.
Organizational Functions - the organization breakdown
of a business or organization by function or responsibility
Business Relationships - the intensities and types of
other companies or organizations a business deals with; including customers,
vendors, regulators, associations, partners etc.
Business Issues & Events - economic, legal,
M&A, regulatory, environmental, labor, safety, other government interfaces,
etc.
Products & Services - products sold; MRO
materials; indirect services, direct materials & services purchased.
Technologies - applicable to the industry or
industries in which the firm participates. Basic or applied sciences are also
included as appropriate.
Geography – referring to location, particularly
region or jurisdiction.
Document or Record Types - this perspective provides
valuable reduction of results based upon the document’s purpose and its
connection to the information need.
In the realm of digital resources, Noy and McGiness (2001) suggest that taxonomies are particularly useful: i) to share common understanding of the structure of information among people or software agents; ii) to enable reuse of domain knowledge; iii) to make domain assumptions explicit; iii) to separate domain knowledge from the operational knowledge; iv) to analyze domain knowledge.
Hence, corporate taxonomies have indispensible roles in the organization of business knowledge. The bottom-line, underlying check of what constitutes a good taxonomy is whether or not the knowledge sharing process is facilitated. There are methods and tools which help verify and validate that such sharing is indeed taking place. In the next section of this article, some of these building blocks are described.
The components of developing corporate taxonomies are best understood by reviewing both the research literature as well as industry efforts; namely, key standards, metadata, classifiers, expertise locators and taxonomy tools available for automating what could be a massive undertaking. Taxonomy structures typically have the following elements: lists of standard terms; hierarchical relationships; and cross references (Graef 2001). No discussion on taxonomies is therefore complete without an understanding of some of the fundamental vocabularies of knowledge organisation and how they are derived.
In creating corporate taxonomies, a practitioner makes use of metadata to describe documents and other resources thereby enabling a richer means of defining the context of the resource and to provide more information access points to support information query and retrieval operations. This is a technique known as tagging in contemporary parlance. Consequently, several metadata schemes have been developed by library and information professionals such as those mentioned above (for example, MARC formats, AACR catalogue formats, subject headings such as LCSH, SSH, and classification schemes (DDC, LC). Weibel and Lagoze (1997) [cited by Hillmann (2007)] conclude that: "The association of standardised descriptive metadata with networked objects has the potential for substantially improving resource discovery capabilities by enabling field-based (e.g. author, title, abstract, keywords) searches, permitting indexing of non-textual objects, and allowing access to the surrogate content that is distinct from access to the content of the resource itself." This is of course the primary purpose of developing a taxonomy in the first place, and the point being made is that such associations allow the k-auditabilty of resource discovery and knowledge sharing.
Where knowledge is not explicit, pointers to their (tacit) sources are needed. To this end, expertise locators (euphemistically known as electronic yellow pages) have emerged in the corporate world as means to identify sources of specific expertise and skills. These can be classified or categorized to be included in corporate taxonomies. Grey (1999) suggests that corporate yellow pages (often incorporated into taxonomies) give the highest return on investment and it is easy to understand why. The nature of knowledge work is such that most professionals turn to their peers as the first resort.
Expertise locators are basically lists of the expertise of individuals (usually very highly regarded subject matter experts) in an organisation. Expertise refers to special skills or knowledge of subject embedded in individuals. Hence, an expertise locator becomes a de facto directory of individuals in an organisation with their contact details, designation, and name, along with details about their knowledge, skill sets and experiences. They identify experts in an organisation that are authorities in specific subjects. A subject matter expert may have different levels of expertise in different topics and all this goes into the listing. Such expertise is typically self-reported (on the basis of job responsibilities or qualifications) but sometimes discerned (through formal accreditation or using social network analysis).
The idea of classification emanated from the natural sciences and diffused into library management as reviewed earlier in this article. The proliferation of Internet content and the requirement for opitmised search engines has brought this ancient science into yet another domain that sustains its relevance. Hlava and ven Eman (1999) suggest that most cataloguing schemes – much of which within the English speaking world originating from the UK and US library communities (namely, the OCLC) – use one of 3 methods for classification: original text or idea; existing vocabulary or topic; or a combination. Given the volume of content to be organised, today much of this has to be automated (and continually refined manually) using idea extraction, keyword counts, or adaptive algorithms that discern document context.
Automated classifiers use various proprietary clustering methods to: analyze the content of each document and create concept folders that contain conceptually related documents; organize the concept folders hierarchically based on their interrelationships, and sort each document into one or more concept folder(s) that describe the document in whole or in part (cf. Stratify 2006). Such clustering is typically based on a statistical analysis of all words within a document and extracting keywords or context. Clustered documents are placed within concept folders that contain documents that are “close” or similar, to each other according to a chosen similarity measure which attempts to match the term lists or subject headings (controlled or otherwise) of the documents to a cluster. During search and retrieval, a centroid or representative from each cluster is matched with the requirements of the query, and the entire cluster is retrieved if held similar in the expectation that they are similar and hence must be equally relevant. In this manner the search space is reduced.
It should be noted that classification and cataloging are active, dynamic activities that are never complete (much like arranging the folders of one’s desktop). Hence, there is a continuous process of appending, updating, pruning, and so on, to keep it relevant and useful. A classification may be hierarchic and multi-faceted in order to support multiple perspectives. When recognised that small corporate taxonomies comprise up to a thousand knowledge resource items and large ones greater that twenty thousand (Woods 2004), it is easy to understand why an automatic processor (often times extractor) of metadata and classification rules is necessary. (http://www.searchtools.com/info/classifiers-tools.html is a valuable resource on “Tools for Taxonomies, Browse-able Directories, and Classifying Documents into Categories”.)
In order to select appropriate taxonomy tools that meet specific features or functions, the there need to be a basis for comparison. Table 2 is a list of functionalities and types of features synthesised from the literature (cf. Foo et al. 2007 for a detailed account). A matrix of the availability of these functionalities and features within some of the leading taxonomy tools is available from the authors.
Table 2: Functionalities Of Taxonomy Builders And
Classifiers.
Classification Methods: Rule-based, Training Sets, Statistical Clustering, Manual
Classification Technologies: Linguistic Analysis, Neural Network, Bayesian Analysis, Pattern Analysis/ Matching, K-Nearest Neighbours, Support Vector Machine, XML Technology, Others
Approaches to
Visualization Tools Used: Tree/Node, Map, Star, Folder, None
Depth of The Taxonomy: > 3 levels
Taxonomy Maintenance: Add/Create, Modify/Rename, Delete, Reorganisation/Re-categorization, View/Print
Cross-referencing Support:
Import/Export Taxonomy:
Import/Export Formats Support: Text file, XML format, RDBS, Excel file, Others
Document Formats Support: HTML, MS Office document, ASCII/text file, Adobe PDF, E-mail, Others
Personalization: Personalized View, Alerting/Subscribing
Product integration: Search Tools, Administration Tools, Portals, Legacy Applications (e.g. CRM)
Industry-specific Taxonomy: Business, News, Medicine/Pharmaceutical, Legal, Military, Biotech, Technology, Insurance, Government, Any industry
Access Points to the Information: Browse Categories, Keywords, Concepts & Categories Searching, Topics/Related Topics Navigation, Navigate Alphabetically, Enter Queries, Others
Multilingual Support:
Product Platforms: Window NT/2000, Linux/Unix, Sun Solaris system, Others
The availability of a particular function and existence of a specific feature makes a significant impact on the development of a corporate taxonomy. Besides the obvious requirements fit in terms of Product Platform and Integration, GUI Design, Access Points, Import / Export and Multilingual Support, and so on, there are other nuanced considerations. For example, the easy part of taxonomy implementation is the actual assignment of rules, either from a written “cookbook” for human classifiers, or software. There are basically two approaches to software implementation - those packages that accept and execute rules, and those packages that use statistical techniques (“content like this”) to construct their own rules.
The selection of an appropriate tool is perhaps a matter of efficiency to the trained and experienced organisation but effectiveness as well to many taking the first steps towards a corporate taxonomy. The next section will note that the use of appropriate (and k-auditable) tools is a salient point in the continual evolution of the corporate taxonomy in support of a learning organisation.
3. Mapping And
Taxonomy-Building For Knowledge Audits.
Hence corporate taxonomies may be considered the fundamental basis for knowledge sharing (and specific processes such as create, capture, organize, store, search and transfer) in the organization. They provide a common understanding within the organization that link to the knowledge cycle. Grey (1999) suggests posing the following key questions to the knowledge workers within an organization in order to ascertain the major knowledge flows:
Ø What type of knowledge is needed?
Ø Who provides it and how does it arrive?
Ø How is it improved and re-used?
Ø What happens to new knowledge that is created?
Ø What is prevents the organisation from doing more, better, faster?
Ø How can knowledge flows (therefore) be improved?
This is in effect what is known as a knowledge audit (cf. Liebowitz et al. 2002; NLH 2005) which involves identifying what knowledge is needed, what knowledge already exists, where the gaps lie, who needs the knowledge, and how it will be used. Hylton (2002) more formally states that the knowledge audit is an assessment of how the sum of explicit as well as tacit knowledge within an organisation is exploited throughout the knowledge-cycle and the people and business processes add to such knowledge. More specifically: “The knowledge audit process involves a thorough investigation, examination and analysis of the entire ‘life-cycle’ of corporate knowledge: what knowledge exists and where it is, where and how it is being created and who owns it. It measures and assesses the level of efficiency of knowledge flow. From knowledge creation and capture, to storage and access, to use and dissemination, to knowledge sharing and even knowledge disposal, when the organisation is no longer in need of particular elements of explicit or codified knowledge.
There are two recommended approaches to knowledge mapping (NLH 2005): i) map knowledge resources such as structural, human and relational assets, showing what knowledge exists in the organisation and where it can be found; and ii) include knowledge flows, showing how that knowledge moves around the organisation from source to target (cf. Sharma and Chowdhury, 2007). In both cases, the key is a “map” of corporate knowledge and an accompanying realisation of the value-added during the course of the knowledge flows.
|
1.
What We Know We Know |
2.
What We Know We Don’t Know |
|
core (exploitation) |
blind spot (exploration) |
|
3.
What We Don’t Know We Know |
4.
What We Don’t Know We Don’t Know |
|
seepage |
blue ocean |
|
Knowledge
Content |
|
Figure 2: Using The
Building a knowledge map looks deceptively simple but perhaps requires more effort and resources than any other phase of developing a corporate taxonomy. It is a profound, soul-search that involves the highest level of strategic management and domain expertise to make judgments on fundamental business and knowledge strategies. Figure 2 – the so-called Boston Box from Drew (1999) – shows four quadrants of analysis for a complete coverage of an organisation’s knowledge capital. Quadrant 1 asks what the core competencies of the organization are. Quadrant 3 addresses the unexploited seepage in its knowledge capital repository. Quadrant 2 takes the organizational learning impetus which seeks to position the organization to execute its strategic plans for growth. Quadrant 4 refers to the blind spot of hidden opportunities and threats that may not be (as yet) apparent within the organisation’s leadership. For a symbolic representation, it could be useful to colour code these quadrants in red, blue, green and yellow. Daunting as this analysis may seem, is not a paradigm shift. The point being made in this article is that the organisation of knowledge in the form of a corporate taxonomy carries with it criteria for evaluating possible gaps as well as leaks that need to be plugged. Drew (op. cit.) had captured some of these issues for some time now and the KM community has since developed an entire repertoire of tools for each of these quadrants (cf. Foo et al. 2007 for a textbook coverage of many of these tools).
Combining the numerous approaches from research and practice on taxonomies, classification and ontologies, we have developed a knowledge-cycle driven framework for first understanding and then developing corporate taxonomies for effective exploitation of an organisation’s valuable knowledge resources. The net result of such integration is a dynamic and relevant corporate taxonomy – what Gruber (1993) calls a “portable ontology”. Such a framework also maps classical knowledge flows (create, capture, organise, store, search, transfer and re-use) and inventories (documents, expertise directories, learning communities) with the design of the corporate taxonomy (using automated builders) and knowledge mobilisation (search and re-use). In such a scenario, it is obvious that neither the knowledge flows nor the inventories would be static. Hence it becomes crucial that a methodology for creating knowledge taxonomies adequately supports the notion of continual growth and consequently, auditability. From this framework, we have derived four major steps that need to be undertaken in developing corporate taxonomies with the design objective of knowledge auditability.
Although many refer to Corporate Taxonomies and Knowledge Maps interchangeably, it should be clarified to the discerning reader that they are indeed distinct in the level of detail they carry. At its simplest, a taxonomy is a rule-driven hierarchical organisation of categories used for classification purposes with the appropriate subject headings and descriptors. However, such a simple definition hides the many challenges to be faced in building and maintaining an effective and usable taxonomy for the organisation (Woods, 2004). Corporate taxonomies are particularly used by the various enterprise information systems to permit instant access to appropriate information, where there are voluminous data, and information needs to be managed carefully. K-maps are at best visual aids that help the search and retrieval process. They are the result of what has been described in an earlier section as a knowledge audit – the technical details of which are beyond the scope of this article. Nevertheless, the first step in developing a corporate taxonomy is therefore to conduct a knowledge audit which clearly identifies the creation, capture, organization, storage, search, transfer and re-use of knowledge in the critical business processes of the organization.
Grey (1999) suggests that the key to developing corporate taxonomies is to: “understand that knowledge is transient” and to “recognise and locate knowledge in a wide variety of forms: tacit and explicit, formal and informal, codified and personalised, internal and external, short life cycle and permanent”. It is also imperative to locate knowledge in processes, relationships, policies, people, documents, conversations, links and context, suppliers, competitors and customers.
Lehman (2003) concludes after much introspection that the key
to end use success is precise classifications that are explicitly, completely
and accurately defined. Without such
classifications, most natural languages (vocabularies) and the context of their
usage will defeat all the good intentions of a taxonomy. Classification should be able to be perfect
and should be perfect. “Relative”
quality (some mis-classified and some missed) will destroy user confidence. He states with some conviction: “Avoid
vague, qualitative or descriptive subjects in your taxonomy. Stay with subjects
that are simpler, and are able to be represented by proper names, identifiers
or other unique evidence. Create more and simpler classifications, rather than
fewer and sophisticated classifications.” (op. cit.), observing
that the results of 20 years of cooperative research into better textual query
have yet to produce techniques and languages that consistently find a large
percentage of correct results, and simultaneously avoid a large percentage of
incorrect results.
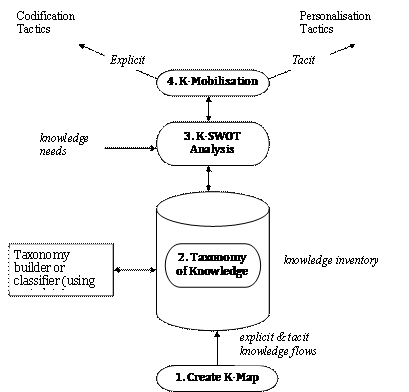
Figure 3: K-Audit Approach.
Figure 3 summarizes the flow of the knowledge audit exercise we propose as a framework for our field investigations. The Step 1 would entail creating a knowledge map of the organization using the Boston Box introduced in Figure 2 to identify corporate knowledge assets in each of the 4 quadrants. Step 2 would create a more complete corporate taxonomy by classifying knowledge residing in corporate repositories along the following dimensions: {structural, human or relational capital}, {core, advanced or innovation knowledge} and {internal or external ownership}.
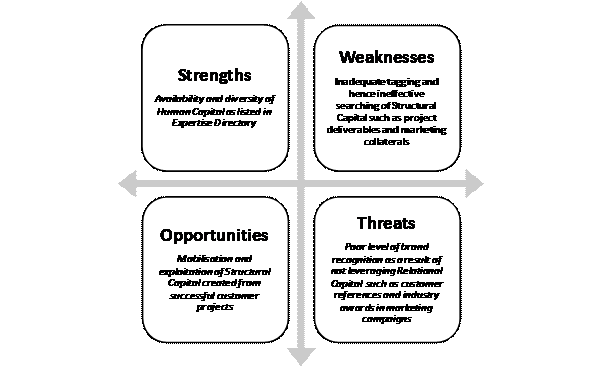
Figure 4: A K – SWOT Example.
Step 3 would involve a strategic exercise known as a knowledge SWOT analysis (Zack 1999) which assesses the organisation’s knowledge strengths, weaknesses, opportunities and threats with respect to competitors. This step is hence closely entwined with the taxonomy obtained from step 2. Figure 4 gives an example of K-SWOT where terse statements in each quadrant reinforces clarity about where an organisation’s knowledge assets are in a relative sense. Step 4 is the final act in the k-audit of ascertaining whether the organization has realized value from its knowledge assets. More specifically, this is a field investigation of the codification and personalization tactics (Hansen et al. 1999) which mobilize the explicit and tacit knowledge assets (respectively) within the organization.
In order to stay relevant and useful, corporate knowledge must be
benchmarked with industry knowledge. The
art of verifying this also falls under the ambit of a knowledge audit. The method we have described above, allows
such an exercise. In the concluding section of this article, we
report our findings in the field and present our results in the form of action
research in using the framework outlined in Figure 3 that may be adopted for a
knowledge audit.
4. Results From The Field.
In this section of the article, using an action research methodology, we described our experiences using the K-Audit approach developed in the previous section in five distinct contexts. These were: 1) a multinational IT services firm whose BI line of business was situated in Singapore; 2) a large software firm which acquired a smaller one and merged the Asia Pacific operations in Hong Kong; 3) an independent study of the national intellectual capital of a major African nation; 4) the development of knowledge policy for another mid size African country; and 5) the Asia Pacific market analysis part of a major IT firm. In each case, the K-Audit that was performed entailed an examination of the critical processes and knowledge assets within the subject of analysis followed by the formulation of actionable recommendations to management. Feedback and assessment on the merit and practicality of the recommendations were actively sought.
As a modification of the steps outlined in Sharma and Chowdhury (2007), the action research proceeded as follows:
1. Kick Off Workshop.
1.1 Determining the Alignment of Organisation and Knowledge Strategies
1.2 Communicating Scope and Objectives of K-Audit
2. High Level KM Self-Assessment.
2.1 Design of K-Map
2.2 Development of Taxonomy of Structural, Human & Relational Capital and categorizing knowledge assets into Core, Advanced & Innovative (cf. Figure 5)
2.3 Verification Knowledge Needs, Inventories & Flows
3. K-SWOT Analysis.
3.1 Mapping of knowledge gaps and redundancies into colour-coded Boston Box
3.2 Identification of strengths, weaknesses, opportunities & threats
3.3 Assessment of Knowledge (Re-)Use
3.4 Development of K-Strategy – max-min, max-max or min-min
4. Recommendations for Knowledge Mobilisation.
4.1 Focus Group Session with Key Executives to present recommendations
4.2 Feedback and Assessment of action research
Table 3: Tabulation Of Knowledge Taxonomy For IT Services
Firm.
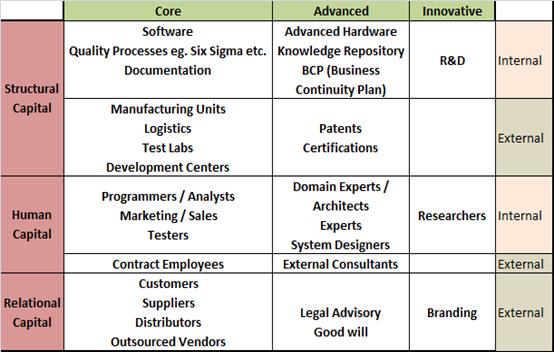
Using the above procedures, we may generalise our field experiences with some terse narratives. In all five contexts of the action research, the kick-off workshop was facilitated by diagrammatic sketches of the organisations’ (or country’s) current knowledge assets. These assets in turn were readily identifiable when categorised into the four quadrants of the Boston Box. The K-Audit was hence scoped as an exercise in determining gaps, blind spots, seepages and the blue ocean. On another level, in step 2, the assets were re-classified into the SC-HC-RC and core-advanced-innovative matrix. Table 3 shows an instance of such a matrix which was the output from one of the action research contexts. This exercise forced knowledge managers to address the difficult question of whether the knowledge inventory of the organisation (or country) was of sufficient quality and served as a preamble for the subsequent K-SWOT. Reflecting on current knowledge inventories versus future needs (aligned to organisation strategy) had the same intended effect. The analysis of knowledge flows were meant to ascertain whether the organisation (or country) was overly reliant on external sources for core knowledge (or innovative knowledge for that matter). The worst case scenario was when an organisation sought external sources for assets it already possessed but was not aware of.
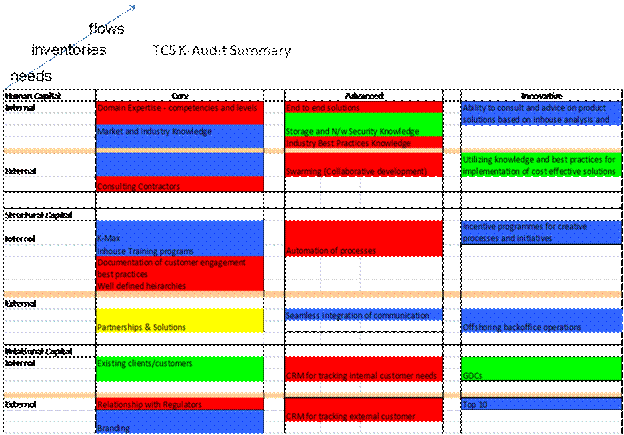
Figure
5: Colour Coding The Taxonomy Of
Knowledge Assets For K-SWOT.
The steps 1 and 2 thus led to a deep and
meaningful K-SWOT which revealed gaps and redundancies in knowledge which must
be overcome. To illustrate, Figure 4
shows the outcome of the taxonomy construction and verification of current
inventories, future needs and the flow of knowledge during mobilisation. These assets were colour coded using the
convention established to represent a quadrant of the Boston Box as shown in
Figure 2. A knowledge gap may be defined
as assets that are needed but unavailable internally. A knowledge redundancy occurs when current
assets are either not mobilised (inadequate flow) or not needed in future. Such a representation allowed the formulation
of tactics on whether core knowledge should be deemed passé and innovative be
sourced externally. An assessment of
knowledge re-use confirm such gaps and redundancies.
In all five contexts of our action research,
the K-SWOT that followed the taxonomy building invariably led to the
identification of strengths and opportunity for the purpose of maximization (ie
organizations and countries need to develop such knowledge capacities) and the
parallel identification of weaknesses and threats that needed to be
minimized. This would ordinarily be a
max-min knowledge strategy. However,
where and organization is in an obvious leadership position, the most
profitable strategy would be to maximize strengths and opportunities or a
max-max. At the other end, in a market
trailing position where strengths and opportunities are not formidable, the
min-min defensive strategy must be to minimize both weaknesses and threats.
Such strategy recommendations that spawn from
knowledge taxonomy building and analysis have both face and construct validity
in the eyes of knowledge managers. For
one, it is they who are involved in making judgments on the identification and
categorization of assets, current flows and projections of future needs. The
approach is clear and simple to use both in terms of definitions and
analysis. From our field experiences, we
have reason for conviction that the proposed taxonomy for k-audits yields valid
and usable strategy recommendations.
Therefore it is hoped that a useful approach has been contributed to the
practice of knowledge management.
5. Acknowledgements
The authors are with the knowledge management
programme of the
6. References
Birkinshaw, J. and Sheehan, T. (2002),
"Managing the Knowledge Life Cycle", MIT Sloan Management
Review, Fall, 75-83.
Cheung, C.F., Lee, W.B. and Wang, Y. (2005).
A multi-facet taxonomy system with applications in unstructured knowledge
management. Journal of Knowledge Management. 9 (6), 76-91.
Conway, S. and Sligar, C. (2002). Unlocking
Knowledge Assets. Quantum Books,
Delphi Group White Paper (2002). Taxonomy
and Content Classification. Available at
http://www.autonomy.com/content/downloads/ access on 22-May-07.
Drew S. (1999). “Building Knowledge
Management into Strategy: Making Sense of a New Perspective.” Long Range Planning, 32(1) 130-136.
Ernst & Young. What is a Taxonomy? Available at:
http://www.ey.com/global/content.nsf/International/XBRL-What_are_Taxonomies accessed on 22-May-07.
Feldman, S. and Sherman, C. (2001). The
High Cost of Not Finding Information. An IDC White Paper available at
http://www.idc.com.
Foo, S., Sharma, R. and Chua, A. (2007). Knowledge Management Tools and Techniques,
Prentice
Gantz, J.F.
(Project Director). (2007). Expanding Digital Universe: A Forecast of
Worldwide Information Growth Through 2010.
IDC White Paper. Available at:
www.emc.com/about/destination/digital_universe accessed on 22-May-07.
Geisler, E. (2006). “A taxonomy and proposed codification
of knowledge and knowledge systems in organizations.” Knowledge and Process Management, 13
(4), 285-296.
Gilchrist, A. and Kibby, P. (2000).
Taxonomies for business: Access and connectivity in a wired world.
Gilchrist, A. (2001). Corporate taxonomies:
report on a survey of current practice. Online Information Review, 25(2),
94-102.
Graef, J. (2001). Managing taxonomies
strategically. Montague Institute Review. Available at:
http://www.montague.com/abstracts/taxonomy3.html accessed on 22-May-07.
Grey, D. (1999). Knowledge Mapping: a
practical overview. Smith Weaver Smith online article. Available at:
http://www.smithweaversmith.com/knowledg2.htm accessed on 22-May-07.
Gruber, T. R. (1993). A translation approach
to portable ontology specifications. Knowledge Acquisition, 5,
199-220.
Gupta, A. K. and Govindarajan, V. (2000).
Knowledge flows within multinational corporations. Strategic Management Journal. 21,
473-496.
Hansen M., Nohria N., and Tierney T. (1999).
“What’s your strategy for managing knowledge”, Harvard Business
Review, March-April, 106-116.
Hlava, M. and ven Eman, J. (1999). Online
Resources on Intranet Taxonomies.
Available at: http://www.accessinn.com/ilib99/index.htm accessed on
22-May-07.
Hylton, A. (2002). Measuring & Assessing
Knowledge-Value & the Pivotal Role of the Knowledge Audit. Available at :
http://www.providersedge.com/docs/km_articles/Measuring_&_Assessing_K-Value_&_Pivotal_Role_of_K-Audit.pdf
accessed on 22-May-07.
Johnston, P. (2006). Expressing
Lehman, J. “Corporate Taxonomies
101”. New Ideas Engineering
Liebowitz,
Jay, Rubenstein-Montano, Bonnie, McCaw, Doug,
Mohanty, S. and Chand, M. (2005).
“5iKM3 Knowledge Management Maturity Model”. Tata Consulting Services White Paper. Avaliable at:
http://www.tcs.com/NAndI/default1.aspx?Cat_Id=7&DocType=324&docid=419
accessed on 22-May-07.
National Library for Health (NLH) KM
Specialist Library. (2005). Conducting
a knowledge audit by C De Brun.
Available at: http://www.library.nhs.uk/knowledgemanagement/ViewResource.aspx?resID=93807&tabID=290 accessed on 22-May-07.
Nonaka, I. and Takeuchi, H. (1995), The
Knowledge Creating Company,
Nordic Metadata Project. (1999). User
Guidelines for
Noy, N.F and McGuinness, D.L. (2001).
“Ontology Development 101: A Guide to Creating Your First Ontology''.
Stanford Knowledge Systems Laboratory Technical Report KSL-01-05 and Stanford
Medical Informatics Technical Report SMI-2001-0880. Available at:
http://www.ksl.stanford.edu/people/dlm/papers/ontology-tutorial-noy-mcguinness-abstract.html
accessed on 22-May-07.
Perez-Soltero, A., Sanchez-Schmitz, G.,
Barcelo-Valenzuela, M., Palma-Mendez, J.T. and Martin-Rubio, F. (2006).
“Ontologies as Strategy to Represent Knowledge Audit Outcomes.” International Journal Of Technology,
Knowledge And Society. 2 (5), 43-51.
Pepper, S. (2000). “The TAO of Topic
Maps.” Presented at XML Europe
2000.
Potter, S. (2001). Building an
Prabha, C., Connaway, L.S., Olszewski, L. and
Jenkins, L.R. (2007). “What is enough? Satisficing information
needs.” Journal of Documentation, 63 (1), 74-89. Pre-print
available at: http://www.oclc.org/research/publications/
archive/2007/prabha-satisficing.pdf
accessed on 22-May-07.
Ranganathan, S.R. (1924 - present). Dr. S.R.
Ranganathan’s Fifty Years of Experience in the Development of Colon
Classification. Available at: Chowdhury http://www.isibang.ac.in/library/portal/Pages/chp1.pdf
accessed on 22-May-07.
Saeed, H. and Chaudhry, A. S. (2002).
“Using Dewey Decimal Classification (DDC) scheme for building taxonomies
for knowledge organisation.” Journal of Documentation, 58(5),
575-583.
Schwikkard, D.B., and du Toit, A.S.A. (2004),
“Analysing knowledge requirements: a case study”, Aslib Proceedings,
56 (2), 104-111.
Senge, P.M. (1999), The fifth discipline: the
art & practice of the learning organisation, Random House,
Ravi
S. Sharma , Schubert Foo and Miguel Morales-Arroyo, “Developing corporate
taxonomies for knowledge auditability – a framework for good
practices.” Journal of Knowledge
Organisation, 35(1), 2008.
Stratify Whitepaper. (2006). Electronic
Discovery, Search and Concept Organisation. Available at:
http://www.stratify.com/stratify_resources/resources_top.html accessed on
22-May-07.
Vellucci, S. L. (1997). Options for
organizing electronic resources: the coexistence of metadata. ASIS
Bulletin. Available at: http://www.asis.org/Bulletin/Oct-97/vellucci.htm
accessed on 22-May-07.
Vellucci, S. L. (1998).
“Metadata.” Annual Review of Information Science and Technology,
33, 187-223.
W3C Technology and Society Domain. Metadata
Activity Statement. Available at:
http://www.w3.org/Metadata/Activity.html
accessed on 22-May-07
Weibel, S. (1997). “The
Williamson, N. J. (1997). “Knowledge
structures and the Internet.” Knowledge Organisation for Information
Retrieval: Proceedings of the 6th International Study Conference on
the Classification Research,
Woods, E. (2004). “Building a corporate
taxonomy: Benefits and Challenges.” Ovum Expert Advice. Available
at: http://www.metier.dk/downloads/kms/20041019_Ovum01.pdf accessed on
22-May-07.
Yong, Z. (2007). Ontology Resource Page. Available at:
http://people.cs.uchicago.edu/~yongzh/Ontology.html accessed on
22-May-07.
Zack, M.H. (1999), “Developing a
Knowledge Strategy”,
Contact the
Authors:
Ravi S. Sharma,
Melvyn Chia, Vironica Choo, Eyosore Samuel, Wee
Kim Wee School of Communication & Information, Nanyang Technological
University, Singapore