A Practical KM 3.0 System Model With
Semantic Web 3.0 Technology
Te Fu Chen, Lunghwa University
of Science and Technology , Taiwan
ABSTRACT:
Looking at factors like value, scope and expiration date, it shouldn't come
as a surprise that the "collect everything" mentality of KM 1.0 was a
failure. Adding factors like maintenance cost and information overload, it
shouldn't be very surprising that the "share everything" mentality of
KM 2.0 is risking failure as well. We cannot treat knowledge as one thing, but
rather as a diverse range of subjects which can be useful to someone in some
situations. The philosophy of KM 3.0 is focused on the individual, and the use
of knowledge. The study will integrate web 3.0 technology into KM 3.0 system to
collect, share and use valuable knowledge to help people get their job done. Therefore, the study will construct a
practical KM 3.0 system model with semantic Web 3.0 technology. Semantic Web 3.0 is about making all this
technology and content (on the Web) smarter -- by adding semantics to the data
and by adding more smarts to applications so that they can do a better job of
helping humans. Semantic Web 3.0 technology will undoubtedly change how we
interact and access information/knowledge both within and outside the firewall
and people. The semantic Web provides an approach that fosters richer
repositories with better and smarter tags. It promises to be a system where
people, knowledge and information co-exist, content is easily searched and
accessed, and information/knowledge is relevant and of high quality. The nature
of your organization should determine the type of knowledge management
system(s) you should implement. Focus should no longer be on simply collecting
or sharing everything and anything, but rather on use to avoid information
overload. Every organization is different, so the study will not provide a
blueprint for everyone to use, but rather give an example of how you could
analyze and determine which knowledge management system(s) that will fit your
organization.
Keywords:
KM 3.0, Social media, Knowledge management, Semantic, web 3.0
1. Introduction
With the increasing popularity of web 2.0 and new social media tools a new term was introduced: "Information overload". It refers to an excessive amount of information available, making it more difficult to separate the useful information from the noise. We are quickly reaching the point where we don't need to collect and share more information, but rather better information (and often less to reduce information overload). Having access to 10 relevant quality documents is much better than having 1,000 irrelevant useless documents. Therefore, KM 3.0 is about having knowledge we can use rather than collecting and sharing as much as possible (Iversen, 2009). Semantic web technology will undoubtedly change how we interact and access information both within and outside the firewall. The semantic Web provides an approach that fosters richer repositories with better and smarter tags. It promises to be a system where people and information co-exist, content is easily searched and accessed, and information is relevant and of high quality. Can we harness semantic web technologies of SIOC (Semantically Interlinked Online Communities), SKOS (Simple Knowledge Organization Systems) or FOAF (Friend of a Friend) and build new, better solutions to knowledge management? This paper aims to bring together theories and practices which seek and research solutions for knowledge management; especially those, which show how semantic web technologies can be used in this context. This paper will discuss how new technologies for knowledge management can impact project management and business models, and discuss further development of knowledge management and Web 3.0.
2. Literature Review
2.1. Web 1.0 To Web 3.0
CEO of Radar Networks in San Francisco: Nova Spivack says: "Semantic Web 3.0 is about making all this technology and content (on the Web) smarter -- by adding semantics to the data and by adding more smarts to applications so that they can do a better job of helping humans”. Web 1.0 – That Geocities & Hotmail era was all about read-only content and static HTML websites. People preferred navigating the web through link directories of Yahoo! and dmoz. Web 2.0 – This is about user-generated content and the read-write web. People are consuming as well as contributing information through blogs or sites like Flickr, YouTube, Digg, etc. The line dividing a consumer and content publisher is increasingly getting blurred in the Web 2.0 era. Web 3.0 – This will be about semantic web (or the meaning of data), personalization (e.g. iGoogle), intelligent search and behavioral advertising among other things.
2.2. KM 1.0 To KM 3.0
Atle Iversen (2009)
defined KM 1.0 focused on collecting knowledge "before it walked
out the door: Many organizations created large knowledge systems, expert
systems, knowledge repositories and intranets to ensure that they captured
their knowledge assets. Most companies didn't really have a clear strategy for
using this knowledge, but at least they made sure that they collected it and
kept it in a database or file somewhere. KM 2.0 focused on sharing knowledge
using web-enabled and social media tools: With the advent of web 2.0, focus
shifted towards sharing, communication and collaboration. The popularity of
social media and web 2.0 tools has started to reach the enterprise, and the use
of these tools in an enterprise setting is often named "
In summary, looking at factors like value, scope and expiration date, it shouldn't come as a surprise that the "collect everything" mentality of KM 1.0 was a failure. Adding factors like maintenance cost and information overload, it shouldn't be very surprising that the "share everything" mentality of KM 2.0 is risking failure as well. We cannot treat knowledge as one thing, but rather as a diverse range of subjects which can be useful to someone in some situations. The philosophy of KM 3.0 is focused on the individual, and the use of knowledge. You want to collect and share valuable knowledge to help people get their job done. Collecting knowledge must be de-centralized, and sharing knowledge must be more focused. Each knowledge worker is an island - there is less common knowledge and more specialized knowledge. Each knowledge worker must collect more for themselves, and less for others. Each knowledge worker is also responsible for reducing the noise and the information overload by focusing more on sharing quality than quantity (Iversen, 2009). Table 1 shows the differences between KM 1.0, KM 2.0 and KM 3.0.
Table 1: The Difference Between KM 1.0, KM 2.0 And KM 3.0
[Mixotricha
(2008); Gurteen (2007); Iversen
(2009)]
|
KM 1.0 |
KM 2.0 |
KM 3.0 |
|
techno-centric |
people-centric |
productivity-centric |
|
command and control |
social |
practical |
|
centralised monolithic systems |
decentralised ecosystems |
personal and decentralised systems |
|
email, newsletters, databases |
social tools (blogs, wikis, IM’s) |
personal, social, practical |
|
KM is extra work |
KM is part of my work |
KM is helping me do my work |
|
IT select the tools |
I select my tools |
We select our tools (IT + I together) |
2.3. Semantic Technologies
According to Wikipedia, in software, semantic technology encodes meanings separately from data and content files, and separately from application code. This enables machines as well as people to understand, share and reason with them at execution time. With semantic technologies, adding, changing and implementing new relationships or interconnecting programs in a different way can be just as simple as changing the external model that these programs share. With traditional information technology, on the other hand, meanings and relationships must be predefined and “hard wired” into data formats and the application program code at design time. This means that when something changes, previously unexchanged information needs to be exchanged, or two programs need to interoperate in a new way, the humans must get involved. Off-line, the parties must define and communicate between them the knowledge needed to make the change, and then recode the data structures and program logic to accommodate it, and then apply these changes to the database and the application. Then, and only then, can they implement the changes (Mazilescu, 2008).
Semantic technologies are “meaning-centered.” They include tools for: auto-recognition of topics and concepts, information and meaning extraction, and categorization. Given a question, semantic technologies can directly search topics, concepts, associations that span a vast number of sources. Semantic technologies provide an abstraction layer above existing IT technologies that enables bridging and interconnection of data, content, and processes. Second, from the portal perspective, semantic technologies can be thought of as a new level of depth that provides far more intelligent, capable, relevant, and responsive interaction than with information technologies alone (Mazilescu, 2008).
2.4. SIOC
(Semantically-Interlinked Online Communities)
Sioc-project.org (2004) indicated the SIOC initiative (Semantically-Interlinked Online Communities) aims to enable the integration of online community information. SIOC provides a Semantic Web ontology for representing rich data from the Social Web in RDF. It has recently achieved significant adoption through its usage in a variety of commercial and open-source software applications, and is commonly used in conjunction with the FOAF vocabulary for expressing personal profile and social networking information. By becoming a standard way for expressing user-generated content from such sites, SIOC enables new kinds of usage scenarios for online community site data, and allows innovative semantic applications to be built on top of the existing Social Web. The SIOC ontology was recently published as a W3C Member Submission, which was submitted by 16 organisations.
2.5. FOAF
And The Semantic Web
Dan Brickley and Libby Miller (2010) indicated FOAF (friends of a friend), like the Web itself, is a linked information system. It is built using decentralised Semantic Web technology, and has been designed to allow for integration of data across a variety of applications, Web sites and services, and software systems. To achieve this, FOAF takes a liberal approach to data exchange. It does not require you to say anything at all about yourself or others, nor does it place any limits on the things you can say or the variety of Semantic Web vocabularies you may use in doing so. This current specification provides a basic "dictionary" of terms for talking about people and the things they make and do. FOAF was designed to be used alongside other such dictionaries ("schemas" or "ontologies"), and to be usable with the wide variety of generic tools and services that have been created for the Semantic Web. The Semantic Web provides us with an architecture for collaboration, allowing complex technical challenges to be shared by a loosely-coordinated community of developers (Brickley & Miller, 2010). FOAF is an application of the Resource Description Framework (RDF) because the subject area we're describing -- people -- has so many competing requirements that a standalone format could not do them all justice. By using RDF, FOAF gains a powerful extensibility mechanism, allowing FOAF-based descriptions can be mixed with claims made in any other RDF vocabulary (Brickley & Miller, 2010).
2.6. Simple Knowledge
Organization System Becomes Semantic Web Standard
Stephen Hui (2009) indicated Simple Knowledge Organization System (SKOS) has become the latest Semantic Web standard. SKOS is “a common data model for sharing and linking knowledge organization systems via the Web”. The W3C’s SKOS primer elaborates: “The Simple Knowledge Organization System is an RDF vocabulary for representing semi-formal knowledge organization systems (KOSs), such as thesauri, taxonomies, classification schemes and subject heading lists. Because SKOS is based on the Resource Description Framework (RDF) these representations are machine-readable and can be exchanged between software applications and published on the World Wide Web”. SKOS has been designed to provide a low-cost migration path for porting existing organization systems to the Semantic Web. SKOS also provides a lightweight, intuitive conceptual modeling language for developing and sharing new KOSs. SKOS can also be seen as a bridging technology, providing the missing link between the rigorous logical formalism of ontology languages such as OWL and the chaotic, informal and weakly-structured world of Web-based collaboration tools, as exemplified by social tagging applications. The aim of SKOS is not to replace original conceptual vocabularies in their initial context of use, but to allow them to be ported to a shared space, based on a simplified model, enabling wider re-use and better interoperability. It’s obviously a technology that’s key to building the Semantic Web (Hui, 2009).
2.7. A Practical KM 3.0 System
Atle Iversen (2009) indicated the nature of your organization should determine the type of knowledge management system(s) you should implement. Focus should no longer be on simply collecting or sharing everything and anything, but rather on use to avoid information overload. Every organization is different, so this paper will not provide a blueprint for everyone to use, but rather give an example of how you could analyze and determine which knowledge management system(s) that will fit your organization. Some knowledge should be captured and shared on a company level, some on a project level, and some knowledge is highly specialized and should not be shared by anyone. The type of knowledge (value, scope, expiration) you collect and share should be evaluated for each level, and the process (collect, cultivate, distribute, apply) should also be adjusted according to level. Each individual should be responsible for his/her knowledge contribution, and editors on each level should be responsible for moderating and sharing across levels (from project to project, from project to department, from division to organization etc). Different levels will probably need different strategies, processes and tools (e.g., company, division, department, group, project, personal level). Most organizations will benefit from having a major KM system for the organization and then some minor KM subsystems for individual departments and/or projects (Iversen, 2009).
2.7.1. Major, Minor And Personal KM
Having all knowledge collected for everyone in a single database usually means that a lot of the knowledge is not useful to you. Finding what you need will be more difficult, and it is easier to feel overwhelmed by the large quantity available (information overload). Separating the knowledge into more specialized knowledge bases will often lead to better targeted knowledge that is easier to handle and find (Iversen, 2009).
A simplified division of different KM systems is shown in Table 2 .
Table 2: A Simplified Division Of Different KM Systems [Iversen
(2009)]
|
|
Use |
Contribute |
Moderate |
Tools |
|
Major KM |
All |
Some |
Few |
Sharepoint or Wiki-based solution for the whole organization |
|
Minor KM |
Many |
Many |
Some |
Wikis and social media (Twitter, IM, Blogs etc) for "local" use |
|
Personal KM: |
One |
One |
One |
PpcSoft iKnow, OneNote, Outlook etc |
Major KM needs to be more formal and organized as it targets many different people in different roles. Minor KM can be more informal and temporary as it is mainly targeted at people in similar roles/groups/projects. Sharing knowledge is easier than Major KM as people have a better understanding of what other people need. Personal KM is the easiest and most efficient as it targets only you - and you are therefore free to collect, cultivate and apply anything you want, in any shape or form you want (Iversen, 2009). Major KM should be similar to Wikipedia: "everybody" use, some contribute, few edit and moderate. A Minor KM system will be more specialized (for a department, a project etc) and therefore have fewer users. However, a larger share of the users will contribute and moderate as they all have a stronger interest in the knowledge. Some organizations will need a strong Major KM and very little Small and Personal KM, while other organizations may be highly fragmented and have little use for Major KM and more use for Small and Personal KM. The level of detail, the quality and the structure of each piece of knowledge depends on which level the knowledge is applied. At the company level the knowledge is usually much more general than knowledge at the project level, as it reaches many more diverse people. At a practical level, each "snippet of knowledge" that is stored and shared should be described with some meta-information about the knowledge (for both Major and Minor KM, but not necessarily for Personal KM) (Iversen, 2009).
2.7.2. IACE Model
The founder of PpcSoft: Atle Iversen (2009) indicated, looking at factors like value, scope and expiration date, it shouldn't come as a surprise that the "collect everything" mentality of KM 1.0 was a failure. Adding factors like maintenance cost and information overload, it shouldn't be very surprising that the "share everything" mentality of KM 2.0 is risking failure as well. We cannot treat knowledge as one thing, but rather as a diverse range of subjects which can be useful to someone in some situations. The philosophy of KM 3.0 is focused on the individual, and the use of knowledge. You want to collect and share valuable knowledge to help people get their job done. He proposed an IACE model to discuss how do people determine which knowledge to keep and share as follows:
Ø Identify what knowledge the employees need to get their job done
Ø Analyze the value, scope and expiration date for each knowledge item
Ø Collect and share the most valuable (worth vs. cost) knowledge first
Ø Explore the best (easiest, most efficient, most useful) way to collect and share each item (depending on scope)
2.8. The Role Of The Semantic Web In Structuring Organizational Knowledge
Mangiuc Dragoş (2009) indicated in order to benefit from the “new wave” of semantic technologies, any modern organization must have a strategic view and also a reasonable understanding of the Semantic Web, XML, Web services, RDF, taxonomies, and ontologies. Each of these technologies has its distinct role in the build of organizational memory and the structure of organizational knowledge. It is the purpose of this paper to provide an opinion on how a company could be driven to take advantage of these technologies now so that it could start gather the rewards of the Semantic Web and prepare for the future. The paper focuses on three areas: diagnosing the problems of information management, providing an architectural vision for a modern organization, and providing some hints of how that vision may come true. A well driven and well managed company will leverage the Semantic Web technologies to craft an information architecture vision, effective over every part of the organization life cycle. The Knowledge-Centric Organization will incorporate Semantic Web technologies into every part of the work life cycle, including production, presentation, analysis, dissemination, archiving, reuse, annotation, searches, and versioning. This section is a hint on how the semantic-oriented knowledge management process should be (see Figure 1).
Figure 1: The
semantic-oriented Knowledge Management Process Search And
Retrieval [Mangiuc Dragoş
(2009)]
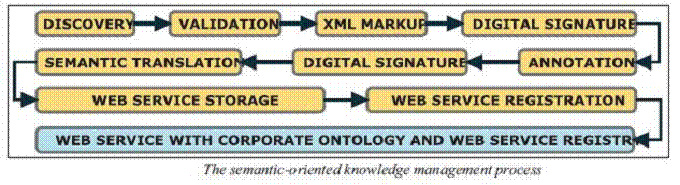
The discovery and production phase is where an individual receives information and intends to translate it into organizational knowledge. The process should be an integral part of the corporate workflow process. This is an area where organizations should be aggressive an greedy in capturing information, because the effectiveness of reuse will be directly proportional to the quantity and quality of information captured. It is important that any new piece of information is marked up with XML, using a relevant corporate schema. Moreover, the individual should digitally sign the XML document using the XML Signature specification to provide strong assurance that the validity of the information has been verified. The annotation process may further arise, the employee may want to use RDF to annotate the new information with own notes or comments, adding to the XML document, but without breaking the digital signature seal of the original material. Finally, the author should digitally sign the annotation with XML signature. It is of main importance that before the information is integrated, its contents to be mapped to topics in the taxonomy and entities in the corporate ontology so that pieces of the information can be compared to other pieces of information in the corporate knowledge base. Once this is done, it is time to store the information in an application with a Web service interface, and any new Web service should be registered in the corporate registry, along with its taxonomic classifications (Mangiuc Dragoş, 2009). As data is stored in an easily accessible format (Web services) and is associated with an ontology and a taxonomy, retrieval of information is much easier than the random process described in the previous section. Integration of all the Web services is not difficult because they all have a SOAP interface, and are registered in a corporate Web service registry; it is easy for an application to find what it is looking for (Berners-Lee et al, 2001).
3. Building
A Practical KM 3.0 System Model With Semantic Web 3.0
Technology
3.1. How To
Get Started
Atle Iversen (2009) indicated which strategy you should use depends on the nature of your business. If you have a lot of knowledge workers, you should probably start with Personal KM. If you run a "franchise-like" business with standardized procedures and processes like McDonalds, you could maybe have a single Major KM system to document and share standard operations throughout the organization. Knowledge Management is a huge field with lots of research, documentation, tools and opinions. Most companies would probably benefit from having a small team who becomes KM experts (both theory and tools) and tries to answer the question: "What common knowledge does people need to get their job done ?" "Common" is a key word here. Collecting and sharing knowledge that won't be re-used by anyone is wasteful and useless. What you want to collect and share is reusable knowledge - knowledge that several people would find useful. The type of knowledge is important - you want high value knowledge with long expiration date collected and shared within the right scope (organization, department, project level etc).
Knowledge workers should start with Personal KM, and if they find it useful then you should consider a Small or Major KM system. If nobody is willing to collect and cultivate their own personal knowledge to get their job done, you shouldn't expect them to collect, cultivate and share knowledge for the rest of the organization. If you create a culture where helping each other is the most important trait, collecting and sharing knowledge could become almost automatic. Find the simplest, easiest to use and most efficient tools available for their needs, and then teach and help them to use them. After you have decided which strategy to use, you could start analyzing what kind of knowledge your employees need to get their job done. Once you have identified what they need, you could start simple by implementing a few of the highest value items first. Start small to avoid information overload and to make it easier to get started with a KM system. Most important criteria when selecting KM tools: Very easy to use ! You need to be able to collect, cultivate, share and find what you need when you need it. And all operations must be very easy to do (Iversen, 2009)!
3.2. A Practical KM 3.0 System
Model With Semantic Web 3.0 Technology
According to above literature
review, the study proposed a practical KM 3.0 system model with Semantic
Web 3.0 technology as Figure 2.
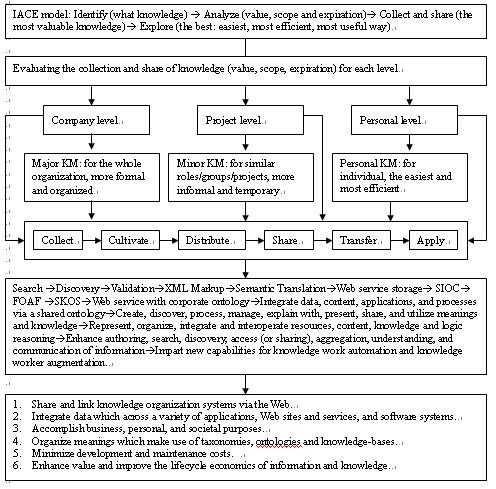
Figure 2: A Practical KM 3.0
System Model With Semantic Web 3.0 Technology
Manu Sporny, et al (2008) indicated key semantic web technology benefits include the following: 1. provides a solid foundation for knowledge representation. 2. vocabularies provide a means of distributed innovation - a cornerstone of the World Wide Web. 3. enables both human-readable and machine-readable semantics to be expressed using a single document. Even providing a minimal amount of semantics in a web page exposes data f or a myriad of known, and yet-to-be-discovered uses. RDF and RDFa allow s companies to innovate in parallel, allowing the market to decide the most popular solution. Current information retrieval techniques on web are not intelligent enough to exploit the meaning of data ie; semantic knowledge within documents and hence cannot give precise answers to precise questions. Semantic web envisions the future web as pages text as well as semantic markup (Abecker et al, 2006). The vision of semantic web is an extension of the current web in which information is given well-defined meaning, better enabling computers and people to work in cooperation (Casteleyn et al, 2006). How could the “semantic” vision come true? Most companies need to change their business process in order to take advantage of semantic web technologies. Luckily, these changes can be gradually implemented, and the organization can easily evolve into a knowledge centric organization. The most challenging aspect may not be the technology; it may be changing the mind-set of the employees. Changing behavior and the ways that all levels think about accessing, integrating, and leveraging knowledge is critical (Mangiuc Dragoş, 2009).
The model is a common data model for sharing and linking knowledge organization systems via the Web. For integration of data across a variety of applications, Web sites and services, and software systems. To create, discover, process, manage, explain with, present, share, and utilize meanings and knowledge in order to accomplish business, personal, and societal purposes. Organization of meanings makes use of taxonomies, ontologies and knowledge-bases. Integrate data, content, applications, and processes via a shared ontology, this minimizes development and maintenance costs. Semantic capabilities enhance value and improve the lifecycle economics of information and knowledge.
4. Conclusions
The most difficult and important part is not the technology, but rather the culture in the organization. Firms need to trust and empower employees to enable them to share their knowledge. If they don't want to collect and share knowledge, they won't! In addition, firms should start small - help each individual improve their own personal productivity and personal knowledge first. If employees start using personal knowledge management firms may continue to the next stage. Ask them what they need in order for them to get their job done, and let them be part of the strategy/process/technology discussion. The KM system is for them - the organization benefits when everybody is doing their job better. Implementing a successful KM system is not easy - but it can give huge rewards for your organization if it helps people get their jobs done! It's time to move on to KM 3.0, and finally solve the real problem (Iversen, 2009). The study is an attempt to identify the role of the semantic web in structuring knowledge at the organization, group and personal level, some knowledge should be captured and shared on a company level, some on a project level, and some knowledge is highly specialized and should not be shared by anyone. The type of knowledge (value, scope, expiration) you collect and share should be evaluated for each level, and the process (collect, cultivate, distribute, apply) should also be adjusted according to level. Each individual should be responsible for his/her knowledge contribution, and editors on each level should be responsible for moderating and sharing across levels (from project to project, from project to department, from division to organization etc). Different levels will probably need different strategies, processes and tools (e.g., company, division, department, group, project, personal level). At the company level the knowledge is usually much more general than knowledge at the project level, as it reaches many more diverse people. At a practical level, each "snippet of knowledge" that is stored and shared should be described with some meta-information about the knowledge (for both Major and Minor KM, but not necessarily for Personal KM).
The study also presents an accurate view of the place where most of the typical large scale organizations are today, and also on the place they need to be in order to become knowledge-centric organizations and leverage the technologies of the semantic web. As a consequence, a knowledge-centric process was defined and a “how-to” roadmap for crafting an organization’s path to the semantic web technology was proposed. Semantic technology functions are to create, discover, represent, organize, process, manage, reason, explain with, present, share, and utilize meanings and knowledge in order to accomplish business, personal, and societal purposes. Semantic technologies represent, organize, integrate and interoperate resources, content, knowledge and logic reasoning. Organization of meanings makes use of taxonomies, ontologies and knowledge-bases. These are relatively easy to modify for new concepts, relationships, properties, constraints and instances. Because semantic technologies integrate data, content, applications, and processes via a shared ontology, this minimizes development and maintenance costs. Semantic capabilities enhance value and improve the lifecycle economics of information and knowledge (Abecker et al, 2006). Semantic enablement of information can enhance authoring, search, discovery, access (or sharing), aggregation, understanding, and communication of information. It imparts new capabilities for knowledge work automation and knowledge worker augmentation. The interoperability and logic reasoning are the capabilities of semantic technologies, from search to knowing.
Ideally, the semantic framework described here will prove useful to the scientific community, and will be adopted to capture semantic meaning in a significant way. In this case, the applications will be able to provide additional interoperability to the related communities, and research capabilities will be significantly enhanced. Beyond that outcome, however, the framework will also enable greater interoperability of systems and knowledge in the entire Internet, as it grows toward an encompassing Semantic Web. This growth of semantic capabilities has been accelerating rapidly in the last few years, and will be increasingly a part of the interactions provided by the World Wide Web, in many cases invisibly to the users. By choosing technologies which are likely to become a basis for the wider Semantic Web, this semantic framework enables the web communities to become engaged, visible, semantically useful contributors to the web itself. (Graybeal, 2008). The most challenging aspect may not be the technology; it may be changing the mind-set of the employees. Changing behavior and the ways that all levels think about accessing, integrating, and leveraging knowledge is critical. Drucker (2008) indicated that the most important contribution management must make in the 21st century is to increase the productivity of knowledge work and the knowledge worker - herein lies our first challenge. How can we dramatically increase the productivity of knowledge work? Ron Young (2003) proposed that the answer is to implement effective knowledge management at all levels, for individuals, teams, organizations and communities, locally, nationally, regionally, and across the globe.
5. Reference
Abecker A., Mentzas G. & Stojanovic L. (2006), Proceeding of the Workshop on
Semantic Web for eGovernment 2006, Workshop at the
3rd European Semantic Web Conference, 12 June, Budva,
Serbia.
Berners-Lee, T., Hendler,
J. & Lassila, O. (2001), The
Semantic Web, The Scientific American, May
Brickley, D. & Miller, L. (2010), FOAF and the Semantic
Web, FOAF Vocabulary Specification 0.97, Namespace Document 1 January 2010 - 3D
Edition, http://xmlns.com/foaf/spec/
Casteleyn, S., Plessers, P. & De
Troyer, O. (2006), “Generating Semantic Annotations during the Web Design
Process,” ACM I-59593-352-2/06/0007 ICEC’06, July 11-14.
Graybeal, J (2008), Architectural Framework and Operational
Concept for Semantic Interoperability,
http://marinemetadata.org/semanticframeworkconcept
Gurteen, D. (2007), Online Information 2007: KM goes Social,
http://www.slideshare.net/dgurteen/km-goes-social-194717
Hui, S. (2009), Simple Knowledge Organization System
becomes Semantic Web standard,
http://www.straight.com/article-248098/simple-knowledge-organization-system-becomes-semantic-web-standard
Iversen, A. (2009), KM 3.0 Part IV: a practical KM system,
http://www.ppcsoft.com/blog/km-3-4.asp
Mangiuc Dragoş, M. (2009), The role of the semantic web in structuring organizational
knowledge, The Journal of the Faculty of Economics - Economic. Volume 4 Issue
1, May, pp. 981-985.
Mazilescu, V. (2008), An Intelligent
Knowledge Management System from a Semantic Perspective, The Annals of the Dunarea de Jos University.
Mixotricha, z. (2008), KM 1.0 KM
2.0 KM 3.0, http://zyxo.wordpress.com/2008/12/28/km-10-km-20-km-30/
Sioc-project (2004), SIOC (Semantically-Interlinked Online
Communities), http://sioc-project.org/
Sporny, M., Longley, D., Johnson, M. & Lehn, D.I.
(2008), Case Study: Establishing an Open, Digital Media Commerce Standard Using
Semantic Web Technologies, Digital Bazaar, Inc., Blacksburg, Virginia, USA.
Young, R. (2003), Knowledge Management - Back
to Basic Principles, Knowledge Asset Management, Springer.
Contact the Author:
Dr Te Fu Chen, Assistant Professor, Department of Business Administration, Lunghwa University of Science and Technology; Email: phd2003@gmail.com