A Computational Narrative Simulation
System For Constructing Multi-linear Narratives In Knowledge Management
W.M. Wang, C.F. Cheung, The Hong Kong Polytechnic University ,
Hung Hom, Kowloon , Hong Kong
ABSTRACT:
Management
of narrative is an important but difficult task. This paper presents a computational
narrative simulation system (CNSS) which is developed by incorporating narrative
analysis, story generation and knowledge-based systems (KBS). It aims
at managing narrative knowledge systemically and constructing narrative
simulation in a multi-linear form automatically. Compare to conventional
methods, CNSS provides not only an important means for maintaining the story database
so that an organization is able to manage narrative knowledge in a
systemic manner. But also, CNSS automatically constructs new scenarios based on multiple
narrative resources with multiple branches. To evaluate the performance of the system,
a
prototype has been built and trial implemented in a social
service company in
Keywords: Computational simulation, AI, Knowledge-based
system, Knowledge management, Narrative generation
1.
Introduction
People make sense of their lives with narratives, which plays a major role in each individual's identification of self (Kerby, 1991). According to Bruner (1991), people also organize their experience and knowing in the form of narrative. Narratives foster learning since they are rememberable, easy to understand and stimulate imagination (Lämsä and Sintonen, 2006). People can have a more comprehensible understanding on their difficulties and challenges by listening to the similar stories from others. These stories help them to adapt to the experience and discover new innovative ideas from others in order to solve their own problems (Bruner, 1991; Polkinghorne, 1988; Ricoeur, 1991).
In organizational perspective, organizational theorists have now become much aware that learning in organizations takes place through narrative knowledge. By collecting stories in a particular organization, by listening and comparing different stories, people gain access to deeper organizational realities, and closely linked to their members’ experience. In recent years, numerous consultants have turned narratives as vehicles for enhancing organizational communication, performance and learning, as well as the management of change (Lämsä and Sintonen, 2006).
In particular, some researchers integrate narrative with simulation and develop the narrative simulation approach. Cole (1997) noted that each story segment presents a probable scenario that requires a series of judgments among alternative actions and provides immediate feedback about the consequences and correctness of the actions selected. Narrative simulations have been found very effective in the education of health behavior (e.g. Cole, 1997), mine safety (e.g. Cole et al, 1998) and agricultural safety (e.g. Morgan et al, 2002).
However, the data acquisition and construction of narrative simulation are labor intensive and time consuming processes. Most data acquisition methods are manually operated such as expert feedback, exercise field tests, individual and focus group interviews, observation, etc. It may take several months or even years to develop a narrative simulation Organizations require up-to-date knowledge to be easily accessed and managed in order to deal with complex, diverse and continuously evolving business environment. Furthermore, the quality of construction of narrative simulation is heavily relied on the experience of the simulation designer. It is inadequate to cope with this fast moving world in which knowledge within organizations is changing rapidly.
On the other hand, there is another stream led by David Snowden. Snowden (2000) mentions that it is now entering a new age of knowledge management, in which there is a new focus on the management of narrative. He states that it is easier, more natural and less onerous to capture narratives than written knowledge. He proposed that narrative databases can be constructed and critically indexed for decision support (Snowden, 2000). The narrative database approach provides an efficient and effective way for managing narratives in organizations. However, the application of the narrative are only focused on navigating and indexing past narratives.
This paper presents a computational narrative simulation system (CNSS) which integrates the narrative database approach and narrative simulation approach. The proposed system incorporates the current technologies used in narrative analysis and story generation, which converts multiple narratives into a multi-linear narrative. The term multi-linear narrative is used in this paper to define a form of multiple linear narratives from a highly structured collection of small narrative pieces. These narrative pieces on their own do not constitute a single narrative path or plotline, but instead they act as building blocks for constructing many different narratives. This type of story defines a form which transcends linear in the sense that it is a form from which many linear stories can be made. Figure 1 shows the structures of traditional narrative structure and multi-linear narrative structure. Multiple branches can be applied at each decision point of the narrative simulation (where decisions or actions need to be made), so that the plot of the story can be changed based on different decisions made by narrative simulation users. This provides richer information than just using a single story.
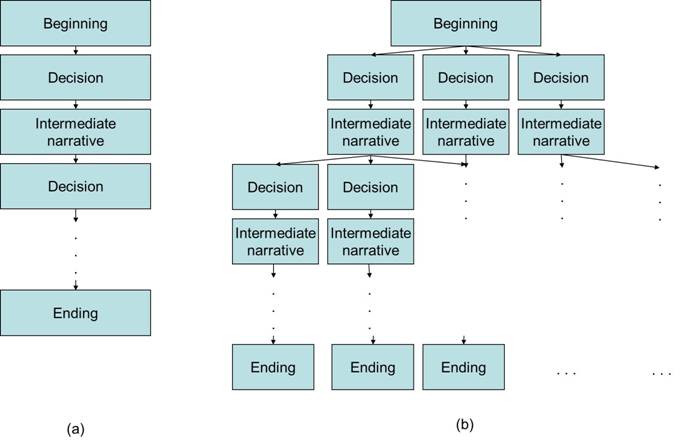
Figure
1: Traditional Narrative Structure (A) And Multi-Linear Narrative Structure (B)
2.
Story Generation
Generation of narrative can be classified into two categories: manual and automatic. In manual modeling, users usually collect stories through interviews, focus group, participant observations and then aggregated into a single narrative based on their knowledge. Although manual modeling can provide users with the most accurate and complicated models, it is terribly time consuming and the quality is heavily relied on the experience of the narrative designers.
Automatic modeling only requires several input parameters to generate narratives. Early systems included TALE-SPIN (Meehan, 1977) and UNIVERSE (Lebowitz, 1985), which produce new stories by changing the initial conditions or story grammars. However, they were only able to generate a limited range of stories within a rigid pre-defined structure of the stories. Some researchers have employed story-grammars to produce automatic storytellers such as GESTER (Pemberton 1989) and JOSEPH (Lang 1997). Story grammars were developed with the objective of creating a theory of story understanding. They represent stories as linguistic objects which have a constituent structure that can be represented by a grammar (e.g. Lakoff 1972, Rumelhart 1975, Mandler and Johnson 1977). However, such kind of systems was only able to produce stories that satisfy its grammar and is not able to modify its knowledge to generate different outcomes. Some other systems such as MINSTREL (Turner, 1993; Turner, 1994), MEXICA (Pérez, 1999; Pérez et al., 2001) and BRUTUS (Bringsjord and Ferrucci 2000) are hybrid systems which consist of integrating different known methodologies into one program.
Recently, more researchers have applied ontology for the generation of
narrative. MAKEBELIEVE (Liu and Singh, 2002) is an interactive story generation
agent that uses commonsense knowledge to generate short fictional texts from an
initial seed story step supplied by the user. The commonsense knowledge is
selected from the ontology of the Open Mind Commonsense Knowledge Base (Singh,
2002). Binary causal relations are extracted from these sentences and stored as
crude trans-frames. By performing fuzzy, creativity-driven inference over these
frames, creative “causal chains” are produced for use in story generation.
Another system named ProtoPropp which applied
ontology of explicitly declared relevant knowledge and case-based reasoning
(CBR) process over a case base of tales for automatic story generation that
reuses existing stories to produce a new story that matches a given user query
(Gervás et al, 2005). A recent model, FABULIST (Riedl et al, 2010) was an architecture
for automating the processes for story generation and presentation. By given a
description of an initial state of the world and a specific goal, the Fabulist
identifies the optimal sequence of actions to reach the goal. They rely on
detailed descriptions of the preconditions and post conditions of all the
possible actions.
To
summarize, the previous research work consists of predefined conditions,
predefined goals, and inferred post-conditions. It requires large amount of
workload for collecting, constructing and maintaining the predefined elements.
The resulted narratives are also limited based on the predefined rules, and
hence, the resulted narratives are rigid and lack of diversification.
3.
The Computational Narrative Simulation System (CNSS)
For the CNSS, a bottom-up and semi-automatic approach was developed for collecting organizational narratives which helps to save the time and reduces the cost of knowledge update. The model converts unstructured narratives into a structured representation for abstraction and facilitating computing processing. By adapting intelligent inference algorithms, decisions and intermediate narratives are generated, so as to achieve the multi-linear narrative structure.
As
shown in Figure 2, the proposed system can be divided into three parts, which are
narrative collection and conversion, construction of multi-linear narrative
background, and construction of decisions and consequences.
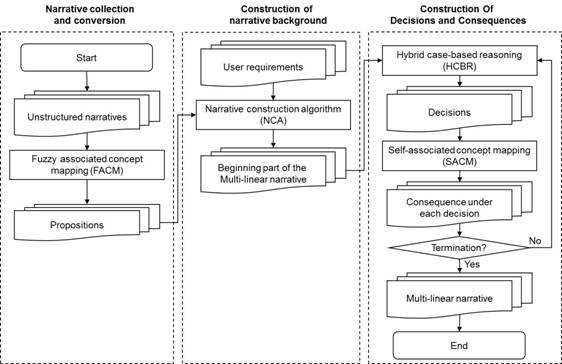
Figure
2: The Multi-Linear Construction Process
3.1. Narrative Collection And
Conversion
The construction of multi-linear narrative starts with the codification of working
cases during the workers’ daily operation. The format of the new case is
business oriented. It could be an enquiry, customer information, or a
transaction, etc. Most cases consist of structured parts and unstructured
parts. The structured parts consist of quantitative parameters, or optional
items which have a range of well defined choices from which the worker may make
a selection. The unstructured parts consist of narratives. Figure 3 depicts an
example of the structured and unstructured parts of a mental health care case.
The structured parts include date of assessment, father relation with the
client (e.g. good, fair, and bad), etc. The unstructured parts include
psychosocial history, intervention plan of the social worker, etc.
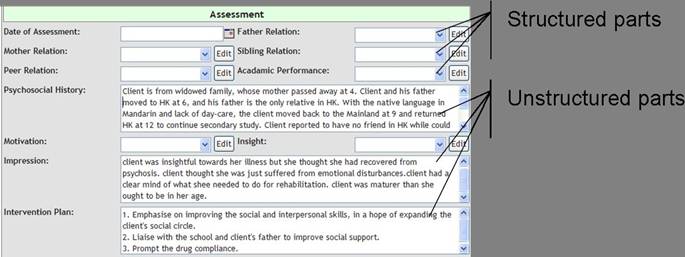
Figure
3: The Structured And Unstructured Parts Of A Case
The unstructured
parts are converted into a structured format based on a Fuzzy associated
concept mapping (FACM) algorithm (Wang, et al, 2008b). Each text is
converted into a concept map. An example of concept map is shown in Figure 4.
Each concept pairs is a proposition. As shown in Figure 4, there are 7
propositions, such as “client – have – impairment of functioning”, “client –
have – depressive symptoms”, etc. Hence, the information of cases together with the resulted
concept maps is stored into the knowledge repository.
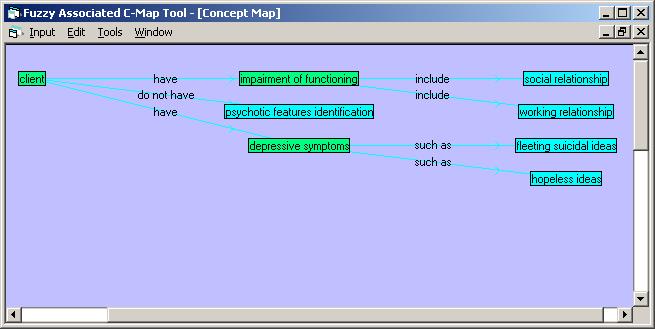
Figure 4:
An Example Of Concept Map
3.2. Construction Of
Background Of A Multi-Linear Narrative
As discussed in Section 1, multi-linear narrative consists of a
beginning (background), and multiple decisions and consequences. The
construction of a background is performed by a narrative construction algorithm
(NCA) (Wang et al, 2009). Multiple texts of background information are
converted into a single background automatically. A schematic
diagram of the NCA is depicted in Figure 5. Based on an adaptive time series
forecasting method (Wang et al, 2009), the expected length of the resultant
background
is determined and a list of weighted propositions is
sorted by the expected values of propositions. For example, it is assumed that
the expected length of resultant narrative is 2, and the top listed 3 propositions are “client’s
academic performance was above average”, “client’s academic performance was
below average”, and “client was diagnosed with psychosis”, respectively. Based
on the conflict resolution of NCA, the 1st and 2nd
propositions are contradicted with each other, and the 1st and 3rd
propositions are not contradicted. As a result, “client’s academic performance
was above average” and “client was diagnosed with psychosis” are selected as
the resultant background.
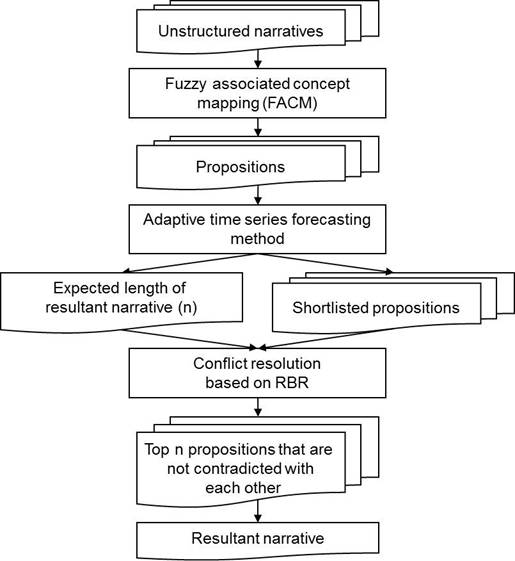
Figure
5: An Illustrative Example Of The NCA
3.3.
Construction Of Decisions and Consequences
A
schematic diagram of construction of decisions and consequences is shown in
Figure 6.
After
the construction of the background of the multi-linear narrative, an inference
engine, Proposition-Based Hybrid Case-based Reasoning (PB-HCBR),
is applied
to infer the decision choices. Then, another inference engine named proposition-based
Self associated concept map (PB-SACM) is used to associate the relevant
concepts related to the inferred decision choice. The associated concepts are then
consolidated to formulate an intermediate narrative. If the intermediate
narrative is not determined as an ending of the multi-linear narrative, the PB-HCBR
is applied again for the inference of decision choices. The loops go on until all decision
choices
have endings.
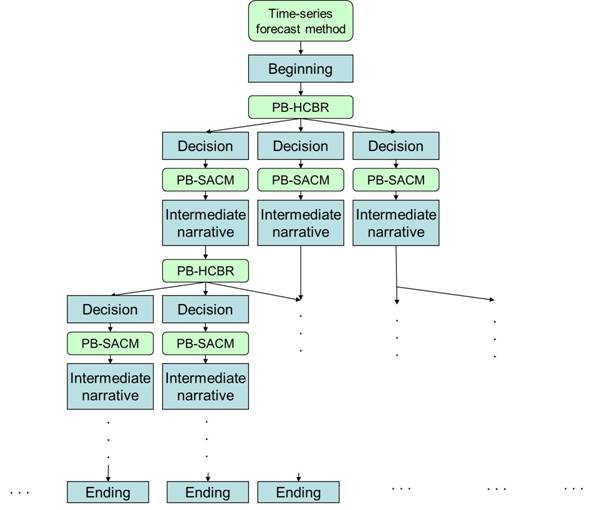
Figure
6: A Schematic Diagram Of The Decisions And Consequences Construction
PB-HCBR is adapted from hybrid case-based reasoning (HCBR) that
presented in Wang, et al (2007). HCBR was an intelligent inference
algorithm by combining aspects of case-based reasoning (CBR), rule-based
reasoning (RBR) and fuzzy theory based on structured data. In this paper, it is
adapted for deducing the decisions of a multi-linear narrative based on
unstructured narrative data. As shown in Figure 7, PB-HCBR is composed of three
main parts which include CBR, RBR and combination of CBR and RBR, respectively.
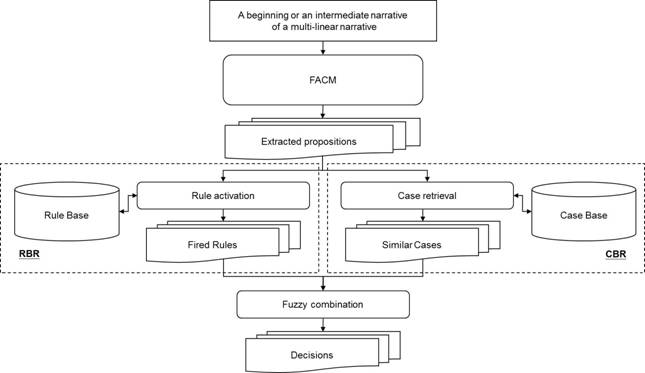
Figure
7: The Schematic Diagram Of Proposition-Based
Hybrid Case-Based Reasoning
In the CBR part, a similarity measure calculates the similarity between the
input propositions and the propositions of the backgrounds or reviews of
previous cases that are stored in the case base. The RBR part consists of a rule
base and an inference engine. The results of CBR and RBR are then combined as the
decisions. An illustrative example of PB-HCBR is shown in Figure 8. It is assumed
that there is a background with 3 propositions (i.e. P1, P2, and P3). Based on CBR, the similarities
between
the background and previous cases are determined. The decision of the most
similar case is then extracted (i.e. D1). On the other hand, a rule is fired
based on matching the rule base in RBR and the decision of the rule is
extracted (i.e. D2). The results are then combined (i.e. D1 and D2).
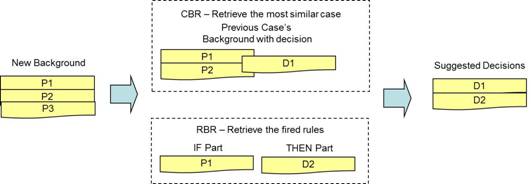
Figure
8: An Illustrative Example Of PB-HCBR
After the generations of decision choices by PB-HCBR, PB-SACM serves as an inference
engine for deducing the intermediate narrative under each decision choice.
PB-SACM is proposed by adapting self-association concept mapping (SACM) that
developed in Wang, et al (2008a). SACM extends the use of concept mapping by proposing the idea of
self-construction and automatic problem solving based on structured
historical records. PB-SACM is being adapted to infer intermediate
narratives based on unstructured narrative data.
The adoption of PB-SACM involves two phrases: learning phase and application phase. In the learning phase as shown in Figure 9, the background narratives, decisions and intermediate narratives are converted into proposition by FACM and then they are aggregated into a PB-SACM format. A PB-SACM is defined with all necessary notations as follows:
Let ![]() , a PB-SACM is a 4-tuple
, a PB-SACM is a 4-tuple ![]() where
where ![]() is a set of
is a set of ![]() distinct proposition
forming the nodes of a PB-SACM,
distinct proposition
forming the nodes of a PB-SACM, ![]() is a function that at
each
is a function that at
each ![]() associates its degree
of importance
associates its degree
of importance ![]() with
with ![]() ,
, ![]() is a function that a
pair of proposition
is a function that a
pair of proposition ![]() associates its degree
of importance
associates its degree
of importance ![]() , with
, with ![]() denoting a weighting
of directed edge from
denoting a weighting
of directed edge from ![]() to
to ![]() ,
, ![]() if
if ![]() , and
, and ![]() if
if ![]() ,
, ![]() represents a set of
degree of association between all concepts in a PB-SACM,
represents a set of
degree of association between all concepts in a PB-SACM, ![]() is a set of parameter
which facilitates the inference, with
is a set of parameter
which facilitates the inference, with ![]() and
and ![]() indicate the maximum
value of
indicate the maximum
value of ![]() and
and ![]() before normalization
respectively, and
before normalization
respectively, and ![]() indicates the total
number of records that have been assimilated to this PB-SACM.
indicates the total
number of records that have been assimilated to this PB-SACM.
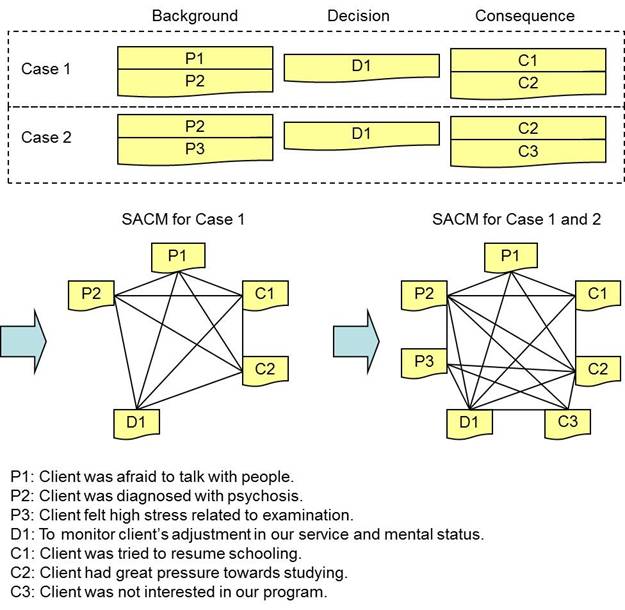
Figure
9: An Illustrative Example Of Learning Phase Of PB-SACM
In the application phase, the
background narrative (constructed by NCA) and decision (constructed by PB-HCBR)
are converted into PB-SACM format. The activation level of each node
of the PB-SACM is then computed. The activated nodes are then combined as the
intermediate narrative of the multi-linear narrative. Following the
example in Figure 9, an illustrative example of PB-SACM application phase is shown
in Figure 10. The propositions of
a background narrative (P1 and P3) and decision (D1) are matched with
the PB-SACM
trained in the learning phase. For example, the propositions C1, C2 and C3
are activated. Based on filtering by a predefined threshold, only C2
is left as the intermediate narrative.
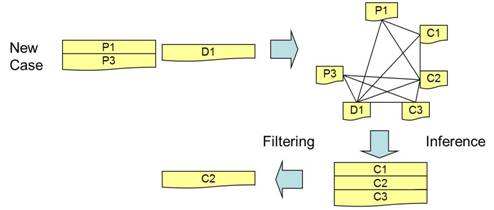
Figure
10: An Illustrative Example Of Application Phase Of PB-SACM
4.
Experimental
Verification
There are two experiments have been carried out for evaluating the proposed system.
The first experiment aims to measure the usability of the proposed system
through a trial implemented in a Department of a social service organization in
During the caring process, social workers interview clients and carry out
diagnostic assessment for evaluating mental health status of the clients. The
social worker is required to write a small narrative into the system to
describe the problem of the client. Based on the presented problem, the social
worker derives the treatment plan and helps the client to establish the
determined goals. Until the client’s condition is satisfied, the case will be
reviewed periodically to evaluate the progress and adjust the treatment plan.
In
this paper, 72 cases are collected. The cases are first analyzed by
the FACM which converts the narratives into a structured data format. The
information of mental health assessment, development history, suicidal history,
and family background is used and analyzed by NCA, which constructs the beginning
of the multi-linear narrative. The treatment records and review records are
used to deduce the decisions and intermediate narratives, which are analyzed by
the PB-HCBR and PB-SACM algorithms. Finally, the termination records are used
to check the ending of the output narrative. Figure 11 shows a screenshot of the resulted beginning
of the output narrative. The output narrative consists of 6 levels, 40
narrative segments, and 39 decisions.
Figure
11: A Screenshot Of Beginning Of The
Narrative Simulation
The field test of the narrative simulation was conducted with the case
workers of the organization and students of social work. 17 participants
were involved in the experiment. By adapting the narrative simulation evaluation
proposed by (McCrary and Mazur, 1999), ten questions were set and they were
rated from 1 to 5 (5 is highest agreement) on a Likert
scale. The findings are summarized and reported in terms of general agreement
with specific evaluation questions as indicated by user choice of either number
(4) or (5) on the scale, disagreement by choice of number (1) or (2), and
neutral by choice of number (3). The evaluation questions are categorized into
different areas which include veracity, informative, cognitive, usability and
affective. Table 1 summarizes the participant evaluations and includes the
percentage results.
Two
evaluation items are related to veracity which specify
the truth-likeness of the narrative. Although participants were told that this
exercise was formulated on true stories, their perceptions on believing in
the reality of the narrative were important. As a result, one statement stated
that the story was realistic, while the other concerned the extent to
which the users could relate personally to the story. By excluding the neutrals, more people
indicated that they could relate personally and more participants agreed
that
the story was realistic. There was one evaluation statement regarding the
informative nature of the simulation. 64.7% of participants agreed that the
simulation was informative. There were two statements designed to get a sense
of whether participants felt that they have learnt something new and they could
remember important things from the exercise. By excluding the neutrals, more
people believed they had learned something new and 50% of the participants indicated
that
the exercise helped them to remember important things.
Table
1: User Evaluation Results Of The Output Narrative (n = 17)
|
Evaluation
Questions |
Design
Category |
Agree |
Disagree |
Neutral |
|
The exercise is realistic and authentic. |
Veracity |
41.2% |
11.8% |
47.1% |
|
I can relate personally to the exercise. |
Veracity |
41.2% |
11.8% |
47.1% |
|
The content is informative. |
Informative |
64.7% |
11.8% |
23.5% |
|
I learned something new from the exercise. |
Cognitive |
29.4% |
5.9% |
64.7% |
|
It helped me remember important things |
Cognitive |
35.3% |
35.3% |
29.4% |
|
The length of exercise is appropriate |
Usability |
70.6% |
5.9% |
23.5% |
|
The exercise is easy to understand |
Usability |
64.7% |
17.6% |
17.6% |
|
The exercise is interesting |
Affective |
41.2% |
35.3% |
23.5% |
|
The exercise made me feel uncomfortable |
Affective |
17.6% |
23.5% |
58.9% |
|
Overall, the exercise is useful |
Overall |
29.4% |
52.9% |
17.6% |
Two specific statements in the evaluation related to the usability of the
simulation. Those were statements regarding the length of the simulation, and
the ease of understanding. 70.6% of users indicated that the length was
appropriate. 64.7% of participants agree that the simulation was easy to
understand. Two statements intended to understand the extent to which this
experience was interesting and made participants feel uncomfortable. The
results showed that 17.6% of users felt the exercise was interesting with 23.5%
disagreeing. 29.4% of participants felt uncomfortable and 52.9% did not feel
uncomfortable. As a whole, 23.5% of users agreed that the system can improve
their work and that the exercise was useful with 5.9% disagreeing.
The second experiment was carried out to evaluate the effectiveness of the
system by measuring the learning outcome of the users after using the system.
The participants were divided into 2 groups which included an experiment group
(8 participants) and a control group (5 participants). The members of the experimental
group participated in the narrative simulation, and then they were evaluated
through a testing exercise. The participants of the control group were directly
evaluated by the testing exercise, without participated in the narrative
simulation. The questions of the testing exercise were randomly selected from
the cases of the knowledge base of the system and the answer choices were
generated based on the similarity analysis. The selected cases were excluded
from the cases used for building the narrative simulation in order to prevent
the direct matching between the narrative simulation and the test. The testing
exercise was composed of 10 multiple choices questions.
As
shown in Table 2, the average mark of the experimental group was 17% higher than
that of the control group, which inferred that the system can significantly
improve their work. A student’s t-test is also conducted to compare the result
of control group and experiment group. As shown in Table 3, the
averaged accuracy of experiment group was significantly higher than the
averaged accuracy of control group (p=0.04). On the whole, the CNSS has
successfully been implemented in the reference site. The performance of the
system in real life application is found to be good which are substantiated by
the encouraging results obtained.
Table
2: Results Of
Learning Outcome Of The Users
|
Question |
Averaged accuracy of control group |
Averaged accuracy of experiment group |
|
Q1 |
0% |
25% |
|
Q2 |
20% |
25% |
|
Q3 |
60% |
87.5% |
|
Q4 |
40% |
87.5% |
|
Q5 |
40% |
37.5% |
|
Q6 |
20% |
25% |
|
Q7 |
60% |
25% |
|
Q8 |
40% |
50% |
|
Q9 |
40% |
62.5% |
|
Q10 |
20% |
87.5% |
|
Q1 to Q10 |
34% |
51.25% |
Table
3: t-Test: Paired Two Sample for
Means
|
|
Averaged accuracy of control group |
Averaged accuracy of experiment group |
|
Mean |
0.34 |
0.5125 |
|
Variance |
0.036 |
0.077951389 |
|
Observations |
10 |
10 |
|
Pearson Correlation |
0.330350425 |
|
|
Hypothesized Mean Difference |
0 |
|
|
df |
9 |
|
|
t Stat |
-1.941374014 |
|
|
P(T<=t) one-tail |
0.042061817 |
|
|
t Critical one-tail |
1.833112923 |
|
|
P(T<=t) two-tail |
0.084123635 |
|
|
t Critical two-tail |
2.262157158 |
|
5.
Conclusion
In this paper, a computational narrative simulation system is presented by incorporating the knowledge-based systems (KBS) and artificial intelligence (AI) technologies, which aims at converting multiple narratives into a multi-linear narrative. The model offers a dynamic and customizable construction of narrative simulation. The method adopts a semi-automatic method to convert workers’ narratives into structured format and automatically constructing a multi-linear narrative based on the converted narratives. The automatic process facilitates the collection and conversion of narratives, and the time and efforts for a narrative construction can be dramatically reduced so that less experienced narrative designer can be employed.
Experimental
evaluations were carried out by trial implementation of the
computational
narrative simulation system in a social service company in
6.
Acknowledgements
The work described in this paper was fully supported by a grant from the
Research Grants Council of the Hong Kong Special Administrative
7. References
Bringsjord, S. and Ferrucci, D.A. (2000) Artificial Intelligence and Literary Creativity. Inside the Mind of BRUTUS, a Storytelling Machine, Erlbaum (Lawrence), Hillsdale, 2000.
Bruner, J. (1991), “The narrative construction of reality”, Critical Inquiry, Vol. 18, Autumn, pp. 1-21.
Cole, H. P. (1997). Stories to live by, a narrative approach to health behavior research and injury prevention. In D. S. Gochman (Ed.), Handbook of health behavior research: IV. Relevance for professionals and issues for the future (pp. 325-349). New YorkCole, H. P., Vaught, C., Wiehagen, W. J., Haley, J. V., & Brnich, M. J. (1998) Decision making during a simulated mine fire escape. IEEE Transactions on Engineering Management, 45 (2), 153-162.
Gervás, P., Déaz-Agudo, B., Peinado, F., & Hervás, R. (2005). Story plot generation based on CBR. Knowledge-Based Systems, 18(4-5), 235-242.
Kerby,
A.P. (1991). Narrative and the Self.
Lakoff, G.P. (1972). Structural complexity in fairy tales, The study of man 1 (1972) 128–190.
Lämsä, A-M. and Sintonen, T. (2006). A narrative approach for organizational learning in a diverse organization. Journal of Workplace Learning Vol. 18 No. 2, 2006 pp. 106-120
Lang, R. R. 1997. A Formal Model for Simple Narratives.
Ph.D. Dissertation,
Lebowitz, M. (1985). Story-telling as planning and learning. Poetics 14(3):483-502.
Liu, H., and Singh, P. (2002). MAKEBELIEVE: Using
commonsense knowledge to generate stories. In Proceedings of the Eighteenth
National Conference on Artificial Intelligence and Fourteenth Conference on
Innovative Applications of Artificial Intelligence Mandler,
J.M.;
McCrary, N. and Mazur, J.M. (1999) Evaluating Narrative Simulation as Instructional Design for Potential To Impact Bias and Discrimination, Proceedings of Selected Research and Development Papers Presented at the National Convention of the Association for Educational Communications and Technology [AECT] (21st, Houston, TX, February 10-14, 1999); see IR 019 753.
Meehan, J. (1977) Tale-Spin, an interactive program that writes stories. In Proceedings of the Fifth International Joint Conference on Artificial Intelligence, 91-98.
Morgan, S. E., Cole, H. P., Struttman, T., & Piercy, L. (2002) Stories or statistics? Farmers' attitudes toward messages in an agricultural safety campaign. Journal of Agricultural Safety and Health, 8 (2), 225-239.
Pemberton L. (1989) A modular approach to story
generation, in: 4th European ACL,
Pérez, R. Pérez y (1999)
MEXICA: a computer model of creativity in writing, PhD thesis,
Pérez, R. Pérez y and Sharples, M. (2001) MEXICA: A computer model of a cognitive account of creative writing, Journal of Experimental and Theoretical Artificial Intelligence 13 (2001) 119–139.
Polkinghorne, D.E. (1988), Narrative Knowing and
the Human Sciences, SUNY Press,
Ricoeur, P. (1991), “Life in quest of narrative”,
in Wood, D. (Ed.), Narrative and Interpretation, Routledge,
Riedl, M.O., & Young, R.M. (2010). “Narrative Planning: Balancing Plot and
Character.” Journal of Artificial Intelligence Research 39: 217–68.2010
Rumelhart, D.E. (1975) Notes on a schema for
stories, in: D.G. Bobrow, A.M. Collins (Eds.),
Representation and Understanding: Studies in Cognitive Science, Academic Press,
Singh, P. (2002). The public acquisition of commonsense
knowledge. In Proceedings of AAAI Spring Symposium: Acquiring (and
Using) Linguistic (and World) Knowledge for Information Access.
Snowden, D. (2000). The art and science of story or “Are you sitting uncomfortably?”. Part 1. Gathering and harvesting the raw material. Business Information Review, 17(3), 147–156.
Turner, S.R. (1993), MINSTREL: A computer model of creativity and
storytelling, PhD Dissertation,
Turner, S.R. (1994), The Creative Process: A Computer Model of Storytelling, Erlbaum (Lawrence), Hillsdale, 1994.
Wang, W.M., Cheung, C.F., Lee, W.B. and Kwok, S.K. (2007) Knowledge-based Treatment Planning for Adolescent Early Intervention of Mental Healthcare: A Hybrid Case-based Reasoning Approach. Expert Systems 24 (4), 232–251.
Wang, W.M., Cheung, C.F., Lee, W.B. and Kwok, S.K. (2008a) Self-associated Concept Mapping for Representation, Elicitation and Inference of Knowledge. Knowledge-based Systems, Volume 21, Issue 1, February 2008, Pages 52-61
Wang, W.M., Cheung, C.F., Lee, W.B. and Kwok, S.K. (2008b) Mining Knowledge from Natural Language Texts through Fuzzy Associated Concept Mapping, Information Processing & Management, Volume 44, Issue 5, September 2008, Pages 1707-1719
Wang, W.M., Cheung, C.F., Lee, W.B. and Kwok, S.K. (2009) A Computational Narrative Construction Method with Applications in Organizational Learning of Social Service Organizations, Expert Systems with Applications, Volume 36, Issue 4, May 2009, Pages 8093-8102
About the Authors:
W.M. Wang is a Research Associate of Knowledge Management and Innovation
Research Centre in Department of Industrial and Systems Engineering of the
C.F. Cheung is a Professor and an Associate Director of Knowledge Management
and Innovation Research Centre in Department of Industrial and Systems
Engineering of The Hong Kong Polytechnic University. His research interests
include Knowledge and Technology Management; Enterprise Systems; Knowledge
Engineering; Artificial Intelligence; Precision Engineering. He has published
more than 220 research papers in various refereed international journals and
conferences. Email: benny.cheung@polyu.edu.hk