A Multidimensional Model
To Map Knowledge
Luis Alberto Casillas-Santillan,
University of Guadalajara, Mexico
ABSTRACT:
The i-space is an information modeling scope with a three dimensional (3D) structure, designed to map information inside during the process of bringing up useful knowledge from the information grids. It was created by professor Boisot (1998). From the hard sciences approach, the i-space raises in the first stage as a verifier. A tool to map knowledge assets in an abstract semantic-scope. The following stages refer to the capacity of knowledge assets to move along the different dimensions; gathering in this process new meaning and utility. And finally, the knowledge assets could develop a crossover procedure to produce new knowledge assets. The present work is a proposal to extend the i-space model to achieve improvements in two directions: the conceptual and the pragmatic. In the conceptual direction, the model acquires the faculty to map complex representations; in the case of the pragmatic direction, the computer simulation of the model provides a streamlined mechanism to identify and measure knowledge assets.
1. Introduction
The i-space (information space) is an information modeling scope with a three dimensional structure, designed to map information inside during the process of bringing up useful knowledge (awareness) from the information grids. Recognizing and handling knowledge is a complex task, which consist in providing relevance and purpose to the available information (Boisot, 1998). Hence, the i-space is a knowledge interpreter, compiler and generator. It is possible to perform an evolutionary process that allows the progressive refining of concepts and perceptions regarding the knowledge assets represented inside the tool. The present work proposes some extensions to the i-space, these in order to improve its capacity to model the world.
Given the nature of knowledge, it is influenced by the context and depends of complex mechanisms that apparently only humans can perform. Even for a human is difficult to gather the needed knowledge from the information grids. The present work offers a mechanism to unleash the knowledge laying underneath the information. This study is based on the framework presented by Max Boisot (1998), and represents an effort to complement the already completed.
According to the usage of computers in the current societies, a computer simulation for the i-space is worthy. The simulation would be limited by machine's capacity. It will not be able to work completely by itself, some directions and interpretations from the user would be required. Computers lack the common sense to gather by itself the purpose or relevance that promotes the data and information to knowledge, some recommendations can be provide by the machine. Even though, human capacity is required in the last stage of interpretation. Everything is clear when it is understood that human and machines capacities complement mutually. Even in the delicate subject of Culture, information technologies could offer a gently proposal to handle the rich and diverse contextual and historic facts. The i-space helps to understand the different stages undertook by humankind, as well as the progressive evolution through the collective-intellect growing along the history.
2. The i-Space Model
The i-space model provides a mechanism to explain the knowledge flowing through the societies, as well as the understanding process for knowledge handling (Canals, 2002). It is a three dimensional scope. Its dimensions are: codification, abstraction and diffusion (Boisot, 1998). Each dimension represents a complex device oriented to define the kind of knowledge under analysis. The ranges for the dimensions according to Boisot (1998).are:
v Codification - from uncodified to codified
v Abstraction - from concrete to abstract
v Diffusion - from undiffused to diffused
As any formal verifier, the i-space could generate and classify knowledge while it is fed with data, information or even knowledge. In fact, verifying must imply generating: if the i-space can verify certain knowledge, it means that the i-space can generate that knowledge. It is not clear in the reference (Boisot, 1998), but the i-space must be a generator to verify. Generating is an abstract perception regarding the model functionality. The incomes arrive as information, and the abstract machine maps that information according to certain specifications; producing meaningful and useful knowledge as an outcome.
Any knowledge representation can be mapped inside the i-space through this system (Boisot et al, 2000). The model is, at first, activated by humans and therefore requires non ambiguous positions from those involved. Ambiguity is the killer for the understanding. It is possible to have a well defined specification for coding using an abstracting approach and diffusion level, but if ambiguity present... no meaningful answer will be gathered from the model, it can not produce useful knowledge: a knowledge asset.
There are various abstract regions inside the i-space, and every region refers to a different perception of knowledge. In fact, knowledge produces inherently a manifestation; but is the human perception the provider of meaning, and therefore the position setter inside this abstract scope. The goal is to place every knowledge component in some region inside the i-space. These knowledge elements could modify its position, but it depends on the perception developed by the humans interacting with them.
It is possible to model learning cycles inside this abstract
scope. During the transportation of the perception from the most simple and
rustic edge of the i-space
to the most complex one, it operates a continuous learning process in the
person or organization involved. Figure 1 shows an example of the i-space and some knowledge assets.
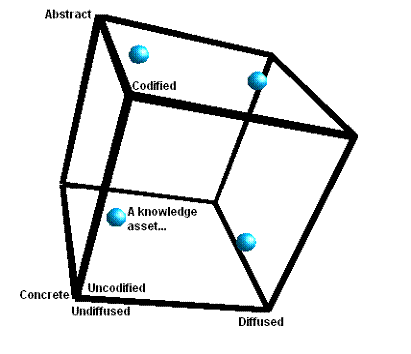
Figure 1: The I-Space And Some Knowledge Assets
(Blue Circles), Adapted
From (Boisot, 1998)
3. Extensions
To The Model
3.1. Adding
A New Dimension
Even when utility has been considered in the original model (Boisot, 1998), it refers to an interpretation implied from the position of the knowledge asset inside the i-space. It is possible to implement the utility dimension to the model. The resulting four dimensions (4D) model is difficult to paint in a two dimensions tool, as a piece of paper. Figure 2 shows the hypercube modeling the extended i-space, which has been constructed according to the technique to draw the following dimension by duplicating the current one and joining all edges by lines.
The 4D i-space model will be able to contain knowledge assets evaluated according the original schema plus the capacity to map the utility. This proposal must raise a set of questions, among the most significant is the paradox regarding the apparent duplicity in the utility perception. The utility can be gathered in the original model from the position of the knowledge asset, therefore there is no apparent justification to add the utility dimension. Nevertheless, by adding a new dimension is possible to multiply the representation capacity of the model along the new dimension; which implies that some knowledge asset can be associated to different utility levels.
By adding the new dimension, it is supported the hypothesis that the utility
influences significantly the hierarchical positioning of the data in the
knowledge hierarchy; which moves from noise to meta-knowledge. Figure 3 shows
this hierarchy (Giarratano & Riley, 2001).
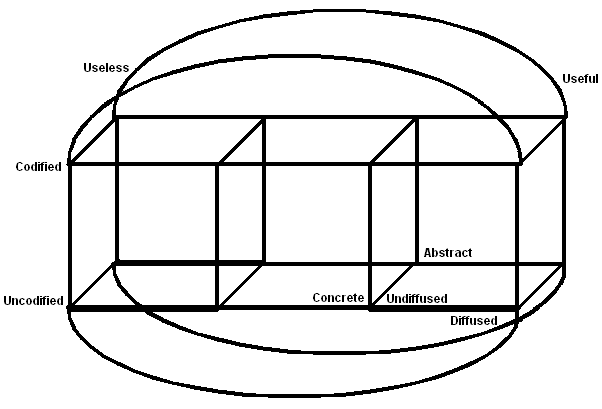
Figure 2: The Extended 4D I-Space, That Includes The New Dimension Utility
3.2. Adding
Fuzzy-logic
Boisot et al. (2000) have already considered the use of agents, which is a brilliant idea. It is a first approach to automate the knowledge management. Nevertheless, machines are unable to successfully manage complex knowledge manifestations. Semantic-networks are the recommended tool to represent knowledge inside a computer, but the nature of computers requires discrete representations; meanwhile reality manifests as a continuum most of the time. Turning to a discrete representation implies information loss and the i-space dimensions manifest as a continuous phenomenon, therefore the i-space would have holes in the knowledge assets detection and management.

Figure 3: The Knowledge Hierarchy (Giarratano & Riley, 2001)
According to computer capacity, computable tasks refer to a set of activities that can be performed by a machine following an algorithm. Those tasks that require a special behavior from the computer, which is away of machine's regular capacity, are considered non-computable; such as “implying with a 100% of certainty, what is the best person to get married”. Conventional activities are those that exploit the “natural” capacities of the machine, without compromising them. Non-conventional activities will, therefore, ask for a response that is “naturally away” of machine's “natural” capacity. At this point, Artificial Intelligence can offer a nice response to the query. When trying to involve a computer in non-conventional activities, the most probable result will be failing. It is not about a pessimistic position, is a realistic one. Computers, agreeing with its machinery essentials, require precise description of the tasks to develop. This description must be constructed using the codification that machine can handle, which are usually composed by low level tokens (sub-symbols). Finally, the description must be free from ambiguity. Building such a description requires certain training and a considerable effort.
Considering knowledge requisites, computers have not the tendency to detect and handle it as they do with data or information. Common sense is required to provide the abstracting capacity to detect and handle knowledge (mainly in the case of tacit knowledge). Just as the problem to classifying apples in different deposits according to the color (red or green) (Kosko, 1993): how would it be manage the problem of classifying an apple with red and green stripes? usually, a person solves the problem sending the apple to the deposit corresponding to the predominant color stripes. A computer following a conventional algorithm would not be able to manage this problem. This is because computers are discrete and deterministic devices, unable to handle chaotic manifestations, based on their regular capacities. It happens the same when a person in perceiving a knowledge asset, the person's capacity allows to solve ambiguous effects; which could not be manage by a computer's lineal algorithm.
The fuzzy logic allows a computer to manage the different levels manifested by every dimension (Del Brio & Molina, 2002). At computer science field, fuzzy logic allows to evaluate the situations when trying to produce an adequate response. This is done through fuzzy sets, which permit to group objects or events based on the value for certain magnitude.
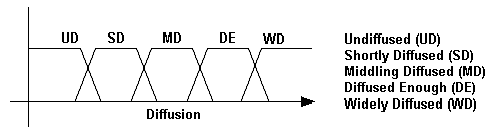
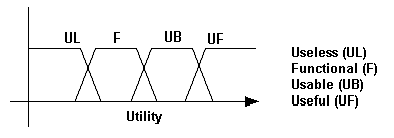
This work is not intended to detail the diverse fuzzy-logic concepts and techniques, rather this is oriented to propose the use of fuzzy sets to accelerate and make precise the knowledge management through the i-space using a computer or computers networks. The different dimension can be treated separately as a fuzzy logic analysis. The table 1 specifies the scale elements for everyone of the four dimensions. Considering those scale elements established in table 1, the figure 4 illustrates the fuzzy logic models that can be designed. The shape of the fuzzy sets may be defined precisely in further works.
|
Dimension / Linguistic Variable |
Scale elements / Fuzzy Sets |
|
Codification |
Uncodified, Pseudo-codified, Fore-codified,
Semi-codified, Codified |
|
Abstraction |
Concrete, Intelligible, Fuzzy, Ambiguous, Abstract |
|
Diffusion |
Undiffused, Shortly Diffused, Middling Diffused, Diffused Enough,
Widely Diffused |
|
Utility |
Useless, Functional, Usable, Useful |
Table 1: The Different Scale Elements (Fuzzy Sets)
For Every Dimension (Linguistic Variable)
3.3.
Working
With Agents
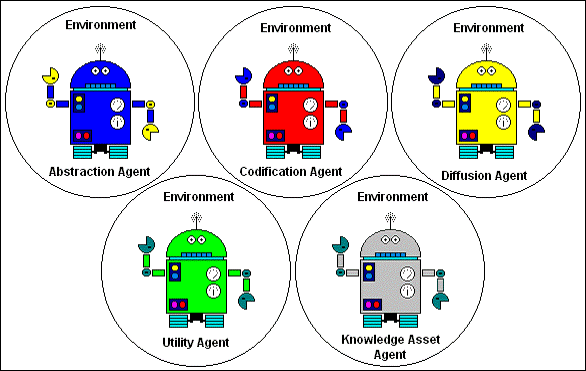
Even though there is already an agent-based proposal (Boisot et al, 2000), the current proposal is for the use of agents to handle the fuzzy-logic when handling knowledge assets, and more flexible rules to exploit the model. The utility factor will be the base for the agents to negotiate. They have been considered a number of agents, developing an equal number of tasks. Figure 5 shows those agents with their occupations in the extended i-space model. Every agent would have a fuzzy logic brain, and they use their understanding capability to build up and update a network of knowledge assets.
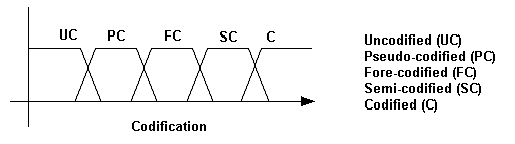
(a)
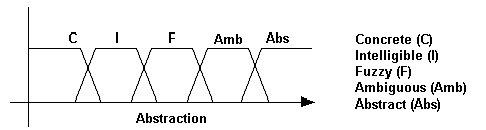
(b)
(c)
(d)
Figure 4: The Different Fuzzy Sets For Every Dimension (Linguistic Variables
(A) Fuzzy Sets For Codification, (B) Fuzzy Sets For Abstraction,(C) Fuzzy Sets For Diffusion, And (D) Fuzzy Sets For Utility.
3.3.1. Negotiation Among The Various Agents
“Negotiation is the process of several agents searching for an
agreement” (
Figure
5. Agents To
Manage Knowledge Assets
An interesting example about utility is that regarding the person trying to buy the house that is by his/her current house. The utility of buying the house aside the one already owned is higher that buying some other house. Therefore, the buyer will be ready to pay a higher price than any other person. Utility is an abstract concept that depends of the desire from those willing to get the good. During the negotiation, the utility must be treated with prudence, to avoid that the supplier realize about the size of the utility that the good represents in the client. In an agent-based model, the agents must propose little by little, even when utility represented is high.
The importance of the utility in the negotiation justifies the new dimension to the i-space. Utility can not depend directly of the value in the original three dimensional i-space, as it was told before: a knowledge asset could be considered useful or useless in either of the edges of the 3D model; according to the relevance, purpose, desire, etcetera of the knowledge asset in the client agent.
3.3.2. Coordination Among Agents
”The process by which an agent reasons about its local actions and the (anticipated) actions of others to try and ensure that the community acts in a coherent manner” (O’Hare & Jennings, 1996). The coordination problem lays in managing the interdependencies between the activities of agents.
The 4D i-space based in multi-agent, is a test-bed that must coordinate the diverse behaviors of the different participating agents, as well as their potential to collaborate. When information is analyzed, the different dimension agents will solve by fuzzy logic techniques the position of the knowledge asset inside the extended i-space. At this moment, is produced a knowledge asset agent responsible to represent a knowledge asset in the extended i-space. During this first stage, the dimension agents coordinate themselves to produce a knowledge asset; finishing with the generation of the agent to manage it. The following stages are devoted to move the knowledge assets through the extended i-space model by the action of the correspondent agents.
Coordination is required because every agent is responsible of certain region in the 4D scope, but regions are overlapped as an effect of the fuzzy approach for the model; therefore some conflicts may arise. It must be understood that coordinating implies the development of a strategy, planning. The plan has to offer a pragmatic solution to the problem of managing knowledge assets. The plan should be constructed over some collaborating premises. Hence, every agent develops a portion of the “great plan” followed by the knowledge managing system as a whole. The preferable coordination mechanism should be a mixture between a hierarchical structure and a teamwork organization. The hierarchical approach is maintained between the dimension agents level and the knowledge assets agents level.
4. Building The Compound Model
In order to build the agent-based model, some roles must be specified; there should be at least three main roles: the domain expert, the modeler and a computer scientist. Each one of them has to deal with different formalisms, ontology and languages.
As it was told in previous sections, managing knowledge represents a deep problem for computers and even for humans is a difficult task. This due to the complex nature of knowledge, -it has been thousands of years discussing this matter. A pragmatic approach to handle this problem is to consider two levels of knowledge: macro and micro. The first (macro) refers to the global perception of the problem, a view from outside. The second (micro) is oriented to the inner characteristics supporting the phenomenon. The objective is to define the goal of the whole system through the definition of every agent’s goal.
The process to formalize knowledge has as main stages: knowledge acquisition, modeling and organizing. Formalizing knowledge will allow its correct management, which consists in providing the right information to the right person at the right time in order for that person to make the right decision. This formalization is most frequently made through networks. The use of this structure to build the knowledge representation is based in a reflection phenomenon: the structure of the human brain is based on neural networks representing knowledge through the inner connections. Knowledge representation can go in two directions: towards problem solving and towards world modeling in general (Barthes, 2002).
It should be considered the use of an ontology. Philosophy and anthropology have a rich approach to define ontology, nevertheless there is smaller and synthetic definition for ontology in the information technologies field. This pragmatic approach for ontology is useful for representing knowledge, which is based in some kind of semantic-network. The idea is to structure the knowledge assets along the semantic dimensions using an ontology. Thus, the ontology is a concepts networks representing a particular domain or set of tasks, which allows indexing and therefore retrieving efficiently the knowledge assets (Barthes, 2002).
Nevertheless, conceptual modeling is not enough to develop the complex task of knowledge managing. Bear in mind the previous paragraphs, which report the intrinsic incapacity of machines to develop the task of managing knowledge by themselves. Human action is required, and this action is not opposed to machine performance. Humans can collaborate through a group ware environment (Boisot, 1998) to provide their skills during the identification of the knowledge assets.
4.1. Conceptual Model
Building the conceptual model is based in constructing an ontology starting
from the recognized knowledge assets. The mechanism consist in prepare the
ideas, concepts and task through triplets with the structure
The proposal is to consider that e1 refers to a object of the world, the relationship to some kind of attribute and e2 is the value for e1 when the relationship happens. Hence, any reality portion could be modeled in a first stage as a list of triplets with the previously defined form. The table 2 tries to model a tiger and some related ideas. This micro-proposal is based in the ideas presented by Marvin Minsky in his classic article (Minsky, 1974).
|
Triplets |
|
ka1(tiger, has/have, stripe*) |
|
ka2(tiger, color, orange) |
|
ka3(tiger, eat/eats, meat) |
|
ka4(tiger, hunt/hunts, food) |
|
ka5(tiger, is/are, feline) |
|
ka6(feline, is/are, animal) |
|
ka7(meat, is/are, food) |
|
ka8(tiger-food, must be, alive) |
|
ka9(tiger-stripe, color, black) |
|
ka10(tiger-stripe, form, irregular) |
|
ka11(carnivore, eat/eats, meat) |
|
... |
Table 2: Triplets Representing Primitive Knowledge
Assets For Tiger
(The Symbol * Means One Or More)
The list of triplets can feed recursively the next triplets until some
semantic level is reached, according to the knowledge manager goal. This
process enables the capacity to represent complex knowledge manifestations. It
is possible to build a graph from the triplets, and the graph is a kind of
semantic-network. Due to the density and weight of the represented knowledge,
this semantic-network can be raised to the level of ontology (An ontology according to its plain concept used in the
information technology field.). Figure
6 sketches the ontology build from some of the triplets.
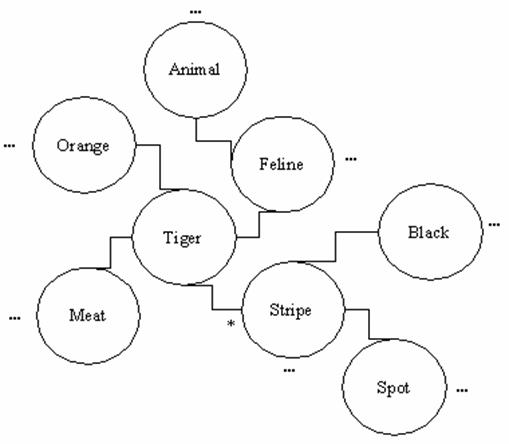
Figure 6: A Segment Of An
Ontology Modeling The Concept Tiger And The Related Ones
A structured representation allows a reliable interchange of knowledge. It is possible to represent some tacit elements when the correct codification is found or developed. The ontology can be organized into layers or frames. Each layer refers to a different abstraction level and a specific codification is required according to that level. Layers connects among them reaching higher abstraction levels, which is a vertical connection. On the other hand, horizontal connections among sub-ontologies imply more complex codifications. The capacity to include a bigger scope through this multi-layered implies a wider diffusion. Finally the knowledge elements represented will have a relative value associated, which depends of the utility established by the persons interacting with those knowledge elements. Might the reader now imagine a multidimensional ontology scattered along the hypercube representing the extended 4D i-space.
4.2. Computer Supported
Collaborative Work (CSCW)
Once the conceptual stage has finished, it is time for the human collaboration to gather all the expertise from those related with the different elements of data and information that are the source to the knowledge elements that will be raised. To achieve this goal, a group-ware tool could provide useful support. Explicit knowledge can be drawn and modified directly by the different participants, implying some effect in tacit knowledge. There are some advantages over the face-to-face meetings. Also there are tools available to directly try to solve problems in real time. Besides, the meetings can be conducted in different time dimensions: synchronous and asynchronous. Meanwhile the distance is not a problem when the Internet is available for the tool. Even with limitations implied by the nonexistence of a face-to-face experience (incapacity to make assumptions from a series of non-codified symbols: gestures, jokes, sarcastic expressions, etcetera), there is a series of advantages supported by the global transformations of the new economy.
Human action over the knowledge assets implies scatter meaning on them. In the case of the group ware formed around the set of knowledge assets, the human collaboration implies a mixed perspective and an overcharged interpretation: higher meanings, but also implies chaos. Nevertheless, entropy is the inner mechanism producing knowledge and its refining through the evolution of concepts and perceptions. Sometimes chaos is feared, but it must be understood that chaos is in most cases the source of rich variety (including the undesired cases).
Besides, involved persons must learn how to reach goals when working using virtual environments; reacting to the tasteless stimuli produced by virtual meetings. It has been chose the expression “tasteless stimuli” to qualify the reaction generated in people when using virtual scopes available in the current machines, this faced with the real life experience. Humans will always privilege the real life experience over any simulation. Different people with experience in virtual collaborative work have been interrogated about their opinion with respect to the experience; they recognize that although were able to fulfill the objectives, it was more complicated and slow than to have had the face to face experience. This implies a challenge for those developing group ware tools.
After listing most of the main defects related to the computer based collaborative work, its advantages prevails in all those cases requiring its qualities: distance solving, large information volumes to manage, recommendation required, automatic coordination, etcetera. It is evident the technology development will head to providing the platforms to support the generation and availability of automatic working environments capable to offer a richer experience during the meetings and workshops.
4.3. The rolls for the agents
The agents described previously have a roll in the model. Those agents responsible of managing the dimensions have the goal to collaborate when determining the region inside the extended 4D i-space. This collaboration consist in using fuzzy logic to establish the influence of every dimension in the process for defining the four-dimensional region in which the knowledge asset is settled, figure 7 sketches this process. During all this time, every knowledge asset (KA) has an agent representing it; this KA-Agent is responsible to inform to the different levels involved its situation, as well as dealing with other KA-Agents to exchange knowledge elements to improve the semantic and relevance of the knowledge represented by all of them.
Every KA-Agent interacts with their counterparts, the dimension agents (D-Agents) and with the people involved. This mechanism (including the inner interactions of the D-Agents group) supports the behavior offered by the system as a whole. The Figure 8 models a subset of the machinery.
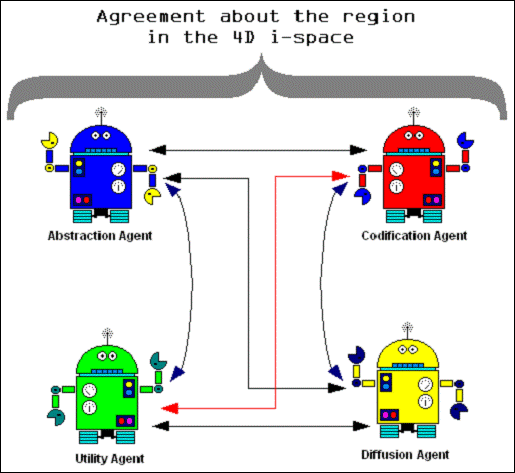
Figure 7: Agents Negotiating To Reach Agreement
Regarding The Region In Which A Knowledge Asset Is
Settled
4.4. Converging
The Different Modules
At the moment, a series of functional blocks have been presented. These thick elements are supposed to couple in order to produce a functional complex-model. If going bottom-up, it is possible to discover the different parts performing their own tasks:
The D-Agents Module provide coherence to the position of the knowledge assets in the extended scope of the 4D i-space. This module represents the GPS (GPS. Referring to Global Positioning System ) for the knowledge assets. Every D-Agent is responsible to gather and interpret the information according to the fuzzy sets established for the corresponding dimension and its nature. The inputs for this agents are the assessments provide by humans, whom have been aided by the self system to evaluate the knowledge asset. The help consists in providing some advices, which are based in the experience collected by the system in previous uses, and the information gathered from the other users trying to evaluate the same knowledge asset.
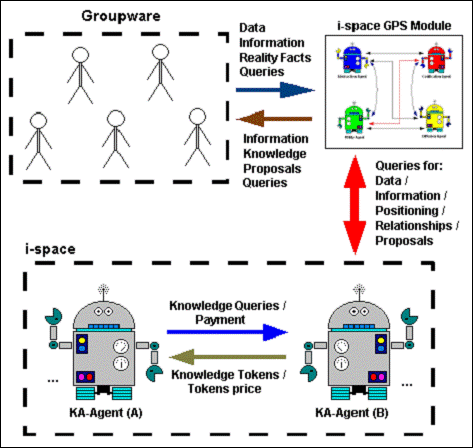
Figure 8: Model For The
Main Interactions Among The Different Actors
On the other hand, KA-Agents are developing their tasks inside an environment in which they form a four-dimensional network. The links among them are established by the ontology supporting the proposed approach for the reality to represent. This type of agents have the capacity to reproduce by mixing those knowledge tokens they represent, just as chromosomes do in the nature for living entities. Humans interacting with the system can establish a set of rules regarding the crossover processes and longevity for those underused knowledge assets, controlling the population growth. The KA-Agents store small parts of knowledge, but there is also knowledge represented by the relationships among them. The goal is to produce a network that represents the reality portion observed by the humans feeding the system, with a considerable fidelity level and the same approach. These KA-Agents can also exchange knowledge tokens to improve or complete its own perspectives, concepts and representations. It is possible to define some hierarchical levels, adding the capacity to have KA-Agents controlling some others KA-Agents; which implies the capacity to represent more complex knowledge assets.
Finally, the group ware is the amalgam that joins all participants in one virtual environment. This tool can hold different intelligence levels (Understanding “intelligence” as the capacity to adapt successfully to the context or environment. Philosophy offer a diverse list of definitions for intelligence. The one considered here is congruent with the evolution theory, and it is related with the concept of fitness.)
. In its simplest representation, the group ware allows various users to establish a virtual space in which they can collaborate to solve problems asynchronously. For the more complex representations of this tool, capacities as: synchronous communications, multimedia interface, recommendation, and even problem solving are available. Considering the proposal presented in this paper, the group ware tool should include at least: synchronous communications and recommendation. Problem solving is a highly desirable capacity for every system, nevertheless the solution for many problems is away from machine's capacity; as it was told before. This group ware tool will collect data and information from all the collaborator, and provide them interpretation and relevance for the inserted inputs; which implies valuable knowledge: knowledge assets.
5. Conclusions
This proposal for extending the original 3D model must have a strong justification. In this case, the scheme has been oriented to achieve improvements in two directions: the conceptual and the pragmatic.
In the first case, conceptual, adding a new dimension allows measuring the utility separately as a new dimension. The main gain in this line, is the affluence to represent diverse knowledge assets with different degrees of utility. This criterion favors the capability to settled various knowledge assets that share the values for the first three dimensions (codification, abstraction and diffusion), but have different values in the utility scale. The effect of not implying the utility directly from the values in the first three dimensions, is a model capable to represent the reality with higher fidelity. Even for similar values in codification, abstraction and diffusion, different persons or organizations will consider an utility level that is congruent with their own expectations, history or goals; therefore different utility levels will be modeled.
The conceptual line was also improved by considering the use of an ontology, from the pragmatic approach. The network of knowledge assets can be systematically built using those valid rules for building an ontology, without going against the knowledge management principles (Formal or empirical ) for handling knowledge assets. The advantages of using this knowledge representation are mainly: the capacity to share knowledge tokens and the availability of a mechanism to reduce the complexity of tacit knowledge.
The pragmatic line of improvement for the model, refers to the use of dedicated agents for handling every dimension of the extended 4D i-space. Everyone of these dimension agents (D-Agents) has a little brain that works using fuzzy-logic. The fuzzy-logic brains allows determining regions inside the 4D i-space, providing a dynamic response. Another kind of agents were considered: knowledge-asset agents (KA-Agents), which are responsible to store, deal, share and evolve knowledge assets. The KA-Agents get together as a cluster to form networks, and the networks get organized to establish interconnected layers of meaning. The clusters of KA-Agents are capable to produce new knowledge by evolving or increasing the knowledge they represent through the various interactions among them. Regarding the pragmatic line of improvement, the present proposal included the use of group ware as it does in (Boisot, 1998). Although, in this case the group ware interacts with the D-Agents module. The group ware will perform the task of acting as the interface between the users and the inner mechanisms to provide interpretation, relevance, utility and organization to the data, information and knowledge inserted by the users to the machinery.
Finally, the D-Agents module is in between the group ware module and the interconnected networks of KA-Agents as an interface providing meaning to both sides.
6. References
Barthès,
J. P. (2002), Knowledge Management and Documents. Proceedings STD (Simpósio
de Tecnologias de Documentos) Saõ Paulo, Brasil, 48(1): 1-7.
Boisot,
M. (1998, Knowledge Assets, Securing competitive advantage in the
information economy.
Boisot, M., MacMillan,
Canals, A. (2002), e-Learning y Gestión del Conocimiento. IV Jornadas sobre
gestión de la información y del conocimiento,
Sociedad Española de Documentación e Información científica (SEDIC); http://www.sedic.es/documentos_boletin_km/4jornadas_acanals.pdf
Del Brio,
B., Molina, A. (2002), Redes Neuronales y Sistemas Difusos. Colombia: Alfaomega, RA-MA.
Giarratano, J., Riley,
G. (2001), Sistemas Expertos, Principios y Programación”. México: Thomson Editores.
Kosko, B., 1993, Fuzzy thinking,
the new science of fuzzy logic.
Minsky, M. (1974), A Framework for Representing Knowledge. The Psychology of Computer Vision, MIT Press. MIT-AI Laboratory Memo 306, June, 1974 ; http://web.media.mit.edu/~minsky/papers/Frames/frames.html
O'Hare, G. M. P.,
Wooldridge, M., 2002, An Introduction to
Multi-Agent Systems.
About the Author:
Luis Alberto Casillas-Santillán is
Professor in the Computer Science Department University
of Guadalajara. He holds a BSc in Informatics,
Contact: Luis Alberto Casillas-Santillan, University of Guadalajara, Department of Computer Sciences, Av. Revolucion, 1500, 44840 Guadalajara, Mexico
Email: lcasilla@mail.fic.udg.mx