Journal of Knowledge Management Practice, Vol.
11, Special Issue 1, January 2010
Papers
Selected From
International Conference On Innovation In Redefining
Business Horizons
Advantages Of Decision Trees Using Data Mining In Indian Retail Industry
Jayanthi Ranjan ¹, Ruchi Agarwal ²
Institute
of Management Technology ¹, Birla
Institute of Technology ², India
ABSTRACT
Indian Retail industry has emerged as
one of the most dynamic and fast paced industries with several players entering
the market. The data that retail industry
collect about their customers is one of the greatest assets of it. Data mining (DM) helps in extracting the buried valuable
information within the vast amount of data. The decision trees using DM
could make a significant difference to
the way in which a retail industry run their business, and interact with their current and prospective customers. The derived
information can be utilized in predicting, forecasting and estimating the
important business decisions, which can help in giving a retailer the
competitive edge over their competitors. The paper
demonstrates the advantages of decision trees using DM in Indian retail
industry with the help of an empirical study.
Keywords: Data mining, Decision
trees, Retail industry, Customers
1. Introduction
In the recent years the significant changes are
done in the retail industry which has important implications on DM. Retail industry is using information technology
(IT) for generating, storing and
analyzing mass produced data not only for
operational purposes but also for enabling strategic decision making to survive
in a competitive and dynamic
environment. DM helps in reducing
information overload along with the improved decision-making by searching for
relationships and patterns from the huge dataset collected by organizations. It
enables a retail industry to focus on the most important information in the
database and allows retailers to make more knowledgeable decisions by
predicting
future trends and behaviors. The DM uses the business data as raw material using a predefined algorithm to search through the vast
quantities of raw data, and group the data according to the
desired criteria that
can be useful
for the future
target marketing (Ahmed, 2004). Through DM and the new knowledge it
provides, individuals are able to leverage
the data to create new opportunities or value for their organizations (Wu,
2002). DM helps in extracting diamonds
of knowledge from the historical data, and predicts future outcomes. Ranjan et
al. (2008) demonstrated the effect of
DM in better decision making in human resource management system. DM helps in
optimizing business decisions.
Berman and Evans (2008) opinioned that data mining is used by retail executives
and other employees and sometimes
channel partners- to analyze information by customer type, product category,
and so forth in order to determine
opportunities for tailored marketing efforts that would lead to better retailer
performance.
Decision trees are well known
methods of predictive modeling used for DM purposes since they provide
interpretable rules and
logic statements which enable more intelligent decision making. Decision trees
create a segmentation of the original data set. The predictive segments that are derived from the
decision tree come with a description of the
characteristics that
define the predictive segment. Thus the decision trees and the algorithms that
create them may be complex, but the results
can be presented in an easy-to-understand way that can be quite useful to the
business user (Berson and Smith, 2008).
Gearj et al.
(2007) demonstrated that decision tree diagramming is a demanding yet flexible
technique which allows
the representation of sequential decisions and subjectively based data in a
readily understood form. Sheu et al. (2008) found that the
consumers' past online shopping experience would directly affect their
decision-making. Yang et al. (2008) use decision tree and association rules to
predict cross selling opportunities.
The arrival of retail boom
caused the global technology vendors to quickly get into the marketplace with
solutions that claim to
make retailers’ lives simpler. Retailers have to put in great efforts to
really know their customers. Retail industry emphasized on quick delivery of customer focused services
(offers, promos, etc) since adapting to customer
needs in a very limited
period of time is also very important. Retailers continuously get the advantage
from information collected
from customers’ transactions. Hence requirements of retail, technology
wise would encompass business intelligence, data mining/warehousing, and other similar technologies
since using these, retailers can constantly benefit from newly observed trends based on user purchases (Sohoni,
2007). The changing consumption
patterns trigger changes in shopping styles
of consumers and also the factors that drive people into stores (Kaur and
Singh, 2007). Hou
and Tu (2008) addressed that the
managers in the contemporary marketing must importantly identify potential
customer relationships to positively
affect corporate performance. Ranjan and Bhatnagar (2008) opinioned that the
optimization of revenue can be
accomplished by a better understanding of customers, based on their purchasing
patterns and
demographics, and better information empowerment at all customers touch
points, whether with employees or other media
interfaces. With the retail boom, companies are likely to deploy IT tools that
help them enhance the end-customer’s
experience. Jones and Ranchhod (2007) expressed that the strategic focus is
required on the real complexity
of the relationship that
organizations are initially able to establish with customers. Sangle and Verma
(2008) opinioned that the customer
relationship management unites the potential of marketing strategies and IT to
create profitable, long-term
relationships with customers and helps in enhancing the opportunities to use
data and information to both
understand customers and co-create
value with them.
The paper proceeds as follows: Section 2 presents
Literature Review. Section 3 explains
Research Methodology. Section 4 discusses about Indian Retail Industry.
Section 5 explains the concept of Data Mining. Section 6 presents advantages of Decision trees in retail industry.
Section 7 concludes the paper.
2. Literature Review
With the retail boom and the
dynamic competitive environment, every retailer must make decisions in the face
of uncertainty, and live
with the consequences. Before making a decision, retailer should analyze the
outcomes of a few alternative actions which help in determining whether a
decision will produce the favorable consequences or not. The consequences of a decision in the
retail industry are analyzed by using a decision tree to gain competitive edge
over the competitors. DM
is being used widely in the context of business but the advantages of decision
trees using DM are not explored.
This is the motivation of our paper.
Sheu et al. (2008) found that
the consumers' past online shopping experience would directly affect their
decision-making. Ranjan
et al. (2008) demonstrated the effect of DM in better decision making in human
resource management system Yang et al. (2008) use decision tree and association
rules to predict cross selling opportunities. Gearj et al. (2007) demonstrated that decision
tree diagramming is a demanding yet flexible technique which allows the representation of sequential decisions and subjectively
based data in a readily understood form. Wang
et al. (2008) found the application of
Decision Trees in Mining High-Value Credit Card Customers.
Sarantopoulos
(2003) described the development and the validation of a decision tree, which
aims to discriminate between good and bad accounts of the customers of a
particular retailer based on a sample of orders placed between certain periods of time. Lemmens and Croux (2006) explored the
bagging and boosting classification techniques which
significantly improved the accuracy in predicting churn. Lima et al. (2009)
showed how the domain knowledge can be incorporated in the data mining process for churn
prediction by analysing a decision table extracted from a decision tree or
rule-based classifier.
Velikova and Daniels (2004) presented methods to enforce monotonicity of
decision trees for
price prediction. Chen and Hung (2009) used decision
trees to summarize associative classification rules. Lee and Siau (2001) reviewed data mining
techniques. Hou and Tu (2008) found that business with customer relationship management practices is linked to
better performance outcomes, including perceptual and financial performance.
Jones and Ranchhod (2007) augmented the concepts from technology-enabled
customer relationship management towards an exploratory framework, designed to explore the nature of
customer attention. Sangle and Verma (2008) identified and analyzed the determinants of adoption
of customer relationship management in Indian service sector. Ranjan and Bhatnagar (2008) presented the benefit
and application of the data mining tools through which the firm achieves competitive advantage by selecting
the best suited data mining tool according to their need.
3. Research Methodology
Decision trees are used for
representing a set of decisions by their tree-shaped structure and can generate
rules for the classification of the dataset. They
are very important for a retailer since it helps in strategic decision making.
The customer transaction data
is very valuable asset for any company hence the need for research design was
felt. So, the data for this paper was
collected in two phase. First the primary data is collected through various
sources which include personal interviews,
surveys and filled questionnaire, review the available online software
packages, attending conferences and seminars, etc. Secondary data is
collected through studying the literature related to research that is available in various journals, books, magazine,
websites, established doctoral thesis, etc.
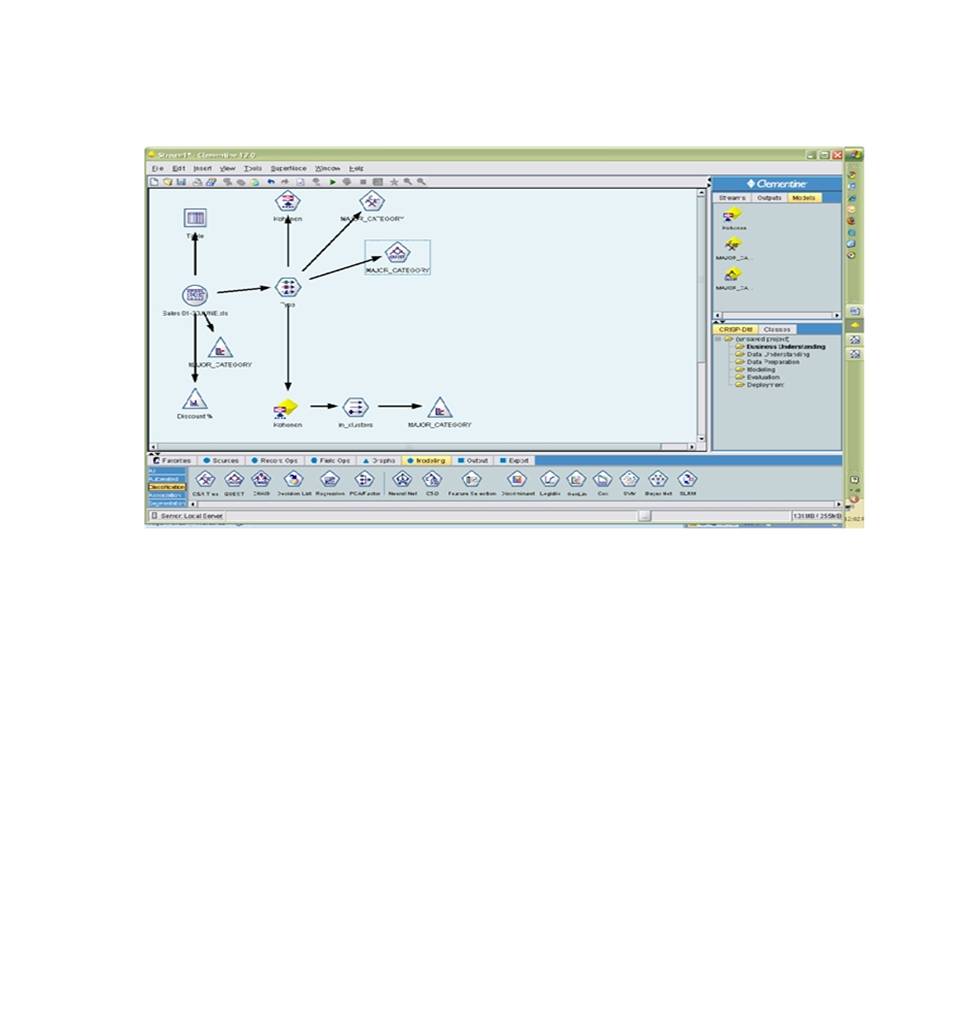
The authors got the customer
transaction database of one retail firm (name masked) which is analyzed with
the help of data mining
tool SPSS’ Clementine. The basic objective is to study the advantages of
decision trees using DM in Indian retail industry with the help of an empirical study.
4. Indian Retail Industry
The increased globalization, market saturation,
and increased competitiveness give rise to mergers and acquisitions. Indian retailers are seeking competitive
advantages by better improving relationships with customers which has taken on new life.
for building customer value, and they
are finally realizing that growing customer value is the key to increasing enterprise value.
The retail sector is growing
rapidly in the Indian scenario as well as globally. With the Indian retail
sector booming, it brings
immense opportunities for foreign as well as domestic players. The changing lifestyle of the Indian
consumer makes it essential
for the retailers to understand the patterns of consumption. The changing
consumption patterns
trigger changes in the shopping styles of consumers and also in the factors
that drive people into stores (Kaur and Singh,
2007). The Indian retail has been transformed due to the attitudinal shift of
the Indian consumer in terms of choice
preference, value for money and the emergence of organized retail formats.
Rising incomes, increased
advertising, and a jump in the number
of women working in the country's urban centers have made goods more attainable and enticing to a larger portion of the
population. At the same time, trade liberalization and more sophisticated manufacturing techniques create
goods that are less expensive and higher quality (Hanna, 2004). Pande
and Collins (2007) explored to
centralize the retail supply chain in
Vector (2007) explored that the Retail is ![]()
![]()
![]()
![]() reported that the estimates predict that the overall size
of the retail sector in
reported that the estimates predict that the overall size
of the retail sector in
5. Data Mining
Data Mining is a process of
analyzing the data from different perspectives and presenting it in a
summarized way into useful information. It
extracts patterns and trends that are hidden among the data. It is often viewed
as a process of extracting valid, previously unknown, non-trivial and useful
information from large databases (Rao, 2003). Han and
Kamber (2007) expressed that the DM is extracting or mining knowledge from
large amount of data. Feelders et al. (2000)
opinioned that the DM is the process of extracting information from large data
sets through the use of algorithms and techniques drawn from the field
of statistics, machine learning and database management systems. Noonan (2000)
explained that DM is a process for sifting through lots of data to find
information useful for decision making. It
helps in predicting the future of the business. It can make the improvement in
every industry throughout the world.
The data can be mined and the results can be used to determine not only what
the customers wants, but to also
predict what they will do. West (2005) addressed that by relying on the power
of data mining, retailers can maintain the consistency and accuracy of their underwriting decisions; they can
significantly reduce the impact of fraudulent claims; and can have a
better understanding of their customer’s wants and needs. It can be used
to control costs as well as contribute to
revenue increases (Two Crows Corporation, 2005).
The DM software uses the
business data as raw material using a predefined algorithm to search through
the vast quantities of raw data, and group the data according to the desired
criteria that can be useful for the future target marketing (Ahmed, 2004). DM involves the use of
predictive modeling, forecasting and descriptive modeling
techniques. By using
these techniques, a retail firm can proactively manage customer retention,
identify cross-sell and up-sell opportunities,
profile and segment customers, set optimal pricing policies, and objectively
measure and rank which suppliers are best
suited for their needs (Bhasin, 2006). DM applications automate the process of
searching the
huge amount of data to find patterns
that are good predictors of purchasing behaviors. After mining the data,
marketers must feed the results into
campaign management software that manages the campaign directed at the defined
market segments (Thearling, 2007).
Wang and Wang (2007) pointed
out that the DM techniques for the online customer segmentation helps in
clustering the customers on the basis of the characteristic that they show
while purchasing the product online or surfing the net. Chen, Wu and Chen
(2005) effectively discovered the current spending pattern of customers and
trends of behavioral change
by using DM tools, which would allow management to detect in a large database
potential change of customer preference, and provide products and services
faster as desired by the customers to expand the client base and prevent
customer attrition. Pan et al. (2007) found that the problem of classification
of the customer is cost sensitive in nature. Consumer-focused companies with sizable caches of
information on current and potential customers such as retailers are ideal for data mining technology
(Cowley, 2005).
Chen and Liu (2005) focused
on enhancing the functionality of current applications of DM. Berry and Linoff
(2001) expressed that
only through the application of DM techniques can a large enterprise hope to
turn the myriad records in its
customer databases into some sort of coherent picture of its customers. It can
also be used to locate individual customers with specific interests or determine the interests of a
specific group of customers (Guzman, 2002). Berman and Evans (2008) opinioned
that DM is used by retail executives and other employees-and sometimes channel
partnersto analyze
information by customer type, product category, and so forth in order to
determine opportunities for tailored marketing efforts that would lead to better retailer
performance.
6. Advantages of Decision
trees in Retail Industry
Decision trees are an
excellent tool in decision-making and DM systems in retail industry. They
provide good service to
any analyst or manager. This is further explained in the following subsections:
6.1. Decision Trees
Decision trees provide an effective method of
decision making in retail industry. Savage (2003) opinioned that the decision trees can sharpen and formalize the
decision-making process. It helps in making the best decisions on the basis of
existing information. Decision trees helps in choosing between several courses
of action. They define a tree structure
in
which leaves represent
classifications and branches represent
conjunctions of features that
lead to those classifications.
This is a very effective structure in which options can be laid and the
possible outcomes of choosing those options
can be investigated. They also help in forming a balanced picture of the risks
and rewards associated with
each possible course of action.
D’Souza (2007) expressed that a decision tree can be learned by splitting
the source data set into subsets based on an attribute value test in which the
process is repeated on each derived subset in a recursive manner and the recursion is completed when either
splitting is non-feasible or a singular classification can be applied to
each element of the derived subset. A
decision tree helps in partitioning the data into smaller segments called
terminal nodes or leaves which are
homogeneous with respect to a target variable. Partitions are defined in terms
of input variables which define a
predictive relationship between the inputs and the target. This partitioning
continues until the
subsets cannot be partitioned any
further using user-defined stopping criteria. By creating homogeneous groups, retailers can predict with greater certainty how
customers in each group will behave.
Decision trees are used in
segmenting groups of customers and developing customer profiles which helps
marketers to produce targeted promotions and achieve higher response rates. The
main goals of data analysis and data mining are to predict future outcomes and identify
factors that can produce desired effect. Sarantopoulos (2003) described the development and the validation of a
decision tree, which aims to discriminate between good and bad accounts of the customers of a particular retailer
based on a sample of orders placed between certain periods of time. Gearj et al. (2007) demonstrated that decision tree
diagramming is a demanding yet flexible technique which allows the
representation of sequential decisions and subjectively based data in a readily
understood form.